
Chapter 1 : Introduction to data versioning#
In this introduction, we will present some concepts behind data versioning and introduce some tools enabling to perform related taks.
Finally, we will focus on DVC which is the data versioning tool we will use in the rest of the tutorial.
What is data versioning ?#
Data Versioning is a technique to track changes made to data over time.
It involves creating and storing different versions of data, allowing users to access and analyze specific versions whenever needed.
Data Versioning ensures data consistency, traceability, and provides a historical record of changes made to datasets.
Traceability#
Track and understand the changes made to the data over time.
This is crucial for compliance, auditing, and debugging purposes.
Reproducibility#
By preserving previous versions of data, Data Versioning enables reproducibility of results.
Users can analyze specific versions of the data used in previous analyses, ensuring consistency and accuracy of research and decision-making.
Collaboration#
Data Versioning facilitates collaboration among data analysts and data scientists.
Multiple users can work on the same dataset simultaneously, knowing they can easily access and switch between different versions without affecting others’ work.
Data Recovery#
In case of data corruption or accidental changes, Data Versioning provides a backup of previous versions, allowing users to recover and restore data to a specific point in time.
What are the tools ?#
In the area of code versioning, there are a few tools available but Git clearly dominates the area.
When it comes to data versioning, a relatively younger field, there are still a lot of available tools.
We won’t focus on enumerating them all here, but we will name the most popular ones and give some pointers:
Lower-level tools#
Git-LFS and Git-annex are two well-known data versioning tools. We consider them as “low-level” here in comparison to DVC and DataLad which offer more complex abstractions built on top of other tools.
They may very well suit your needs depending on the kind of projects you are working on.
In this tutorial, we will focus on machine learning experiments for which we believe that higher-level tools are better suited.
Git-LFS#
Git-LFS replaces large files with text pointers inside Git, while storing the file contents on a remote server.
Git-annex#
Git-annex allows managing large files with Git, without storing the file contents in Git.
It is a lower-level tool than DataLad and DVC which expose higher level abstractions to users.
Higher-level tools#
DataLad and DVC are the two main players in the science data versioning world. DVC’s main audience is machine learning specialists and data scientists while DataLad ‘s main target is researchers.
Datalad#

You can see it as a Python frontend to Git-annex. It provides a lot of useful abstractions to version datasets.
The DataLad handbook is a great resource to learn how to use this tool.
DVC#

DVC is a tool for data science that takes advantage of existing software engineering toolset.
It helps scientific teams manage large datasets, make projects reproducible, and collaborate better.
DVC is written in Python and can be easily installed on the most common OS (Linux, MacOS, and Windows). We will see how to install DVC in the next chapter.
Why DVC ?#
In this tutorial we will rely on DVC rather than on another tool from the list above. There are several reasons we made this choice:
DVC is free and open source.
DVC is very easy to install: it is written in Python and can be easily installed in various ways (pip, brew, conda…).
DVC is the data versioning tool we use in our daily work at Aramis.
The documentation is very good and easy to follow for newcommers.
The commands are very similar to the git commands. This means that anybody used to work with git will be able to work with DVC in no time.
These last points are particularly useful to enbark new contributors in a project relying on DVC for data management.
Warning
DVC does not replace or include Git. You must have Git in your system to enable important features such as data versioning and quick experimentation.
This is both a pro and a con. For this tutorial, we believe this is a strong plus. Indeed, we think that learning to make the difference between what is versioned with Git and what is versioned with DVC is a key point that would ve very valuable even when using DataLad.
What is the target users of DVC ?#
DVC targets people who needs to store and process data files or datasets to produce other data or machine learning models.
In other words, anyone willing to:
track and save data and machine learning models the same way they capture code
create and switch between versions of data and ML models easily
understand how datasets and ML artifacts were built in the first place
compare model metrics among experiments
adopt engineering tools and best practices in data science projects
Try the other tools#
That being said, you might be better using another tool. There are some dicussions (here for example) trying to compare these tools. There is also a very interesting comparison between DVC and Datalad in the DataLad handbook.
We strongly encourage you to make your own opinion by taking a closer look at them yourself:
If you are interested in a low-level data versioning tool and not too afraid by an old-looking documentation, you might be better off with Git-annex
If you are more interested in easily discovering datasets published by others, you might want to try DataLad
For this tutorial, let’s focus on using DVC !
Versionning data and models#
The dirty old way#
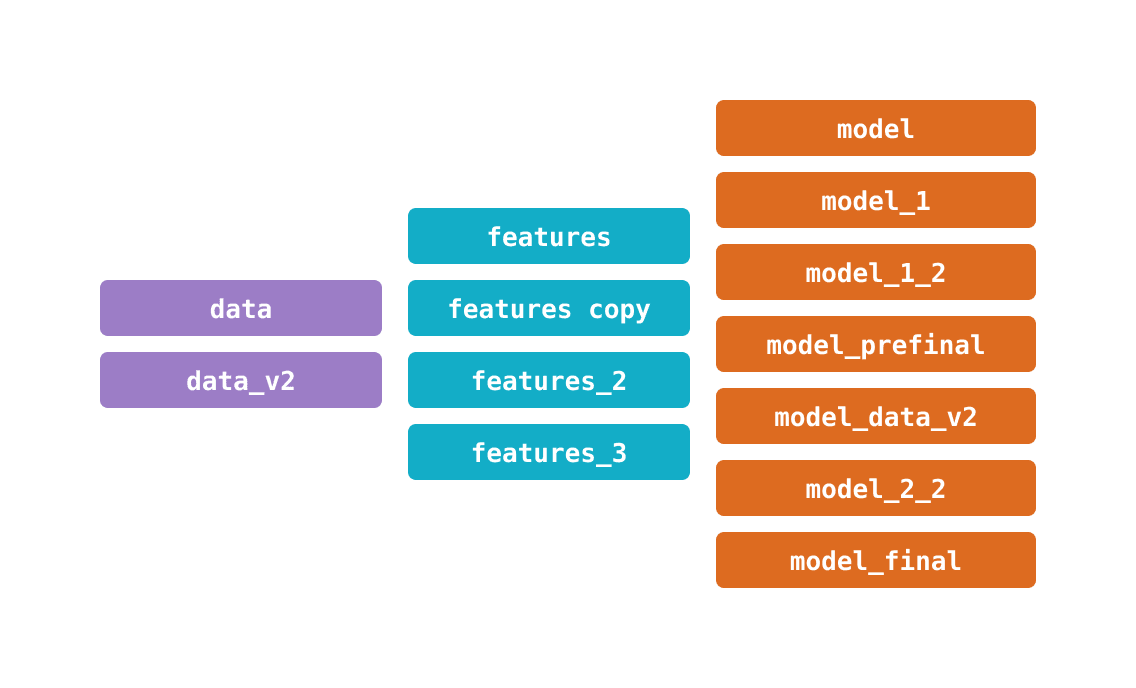
The need for a versioning tool can often be seen through the proliferation of suffixes in the file / folder names. These suffixes usually convey information about:
time (date, version number, revision number…)
author identity
specific milestones (a publication, a conference / workshop…)
This rather primitive style of versioning reaches its limits very quickly for diverse reasons:
the number of files and directories explodes very fast in non trivial cases
the project becomes a mess very fast as people forget what the different names actually meant
the project total weight quickly explodes as everything is copy-pasted
there is no history / lineage, only snapshots in total disorder
In this context, it is VERY difficult to reproduce an experiment. You would have to remember what combination of data, code, model, and set of parameters gave a particular result. For large and long-lasting projects this is almost impossible to do without a proper versioning tool.
The cleaner way#
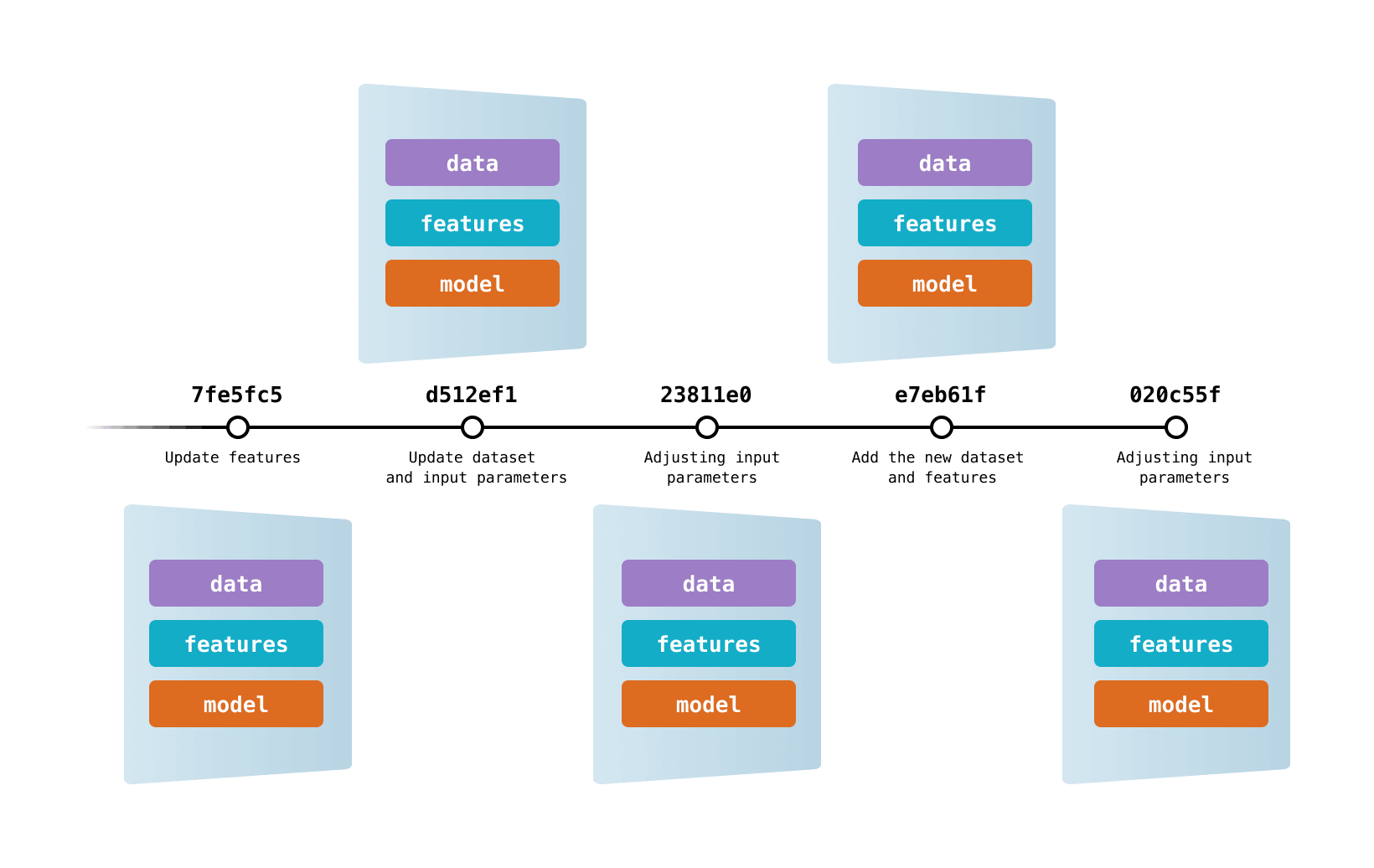
Data Version Control lets you capture the versions of your data and models in Git commits, while storing them on-premises or in cloud storage. It also provides a mechanism to switch between these different data contents. The result is a single history for data, code, and ML models that you can navigate.
As you use DVC, unique versions of your data files and directories are cached in a systematic way (preventing file duplication). The working data store is separated from your workspace to keep the project light, but stays connected via file links handled automatically by DVC.
The benefits of this approach include:
Lightweight: DVC is a free, open-source command line tool that doesn’t require databases, servers, or any other special services.
Consistency: Projects stay readable with stable file names — they don’t need to change because they represent variable data. No need for complicated paths like
data/20190922/labels_v7_finalor for constantly editing these in source code.Efficient data management: Use a familiar and cost-effective storage solution for your data and models (e.g. SFTP, S3, HDFS, etc.) — free from Git hosting constraints. DVC optimizes storing and transferring large files.
Collaboration: Easily distribute your project development and share its data internally and remotely, or reuse it in other places.
Data compliance: Review data modification attempts as Git pull requests. Audit the project’s immutable history to learn when datasets or models were approved, and why.
GitOps: Connect your data science projects with the Git ecosystem. Git workflows open the door to advanced CI/CD tools (like CML), specialized patterns such as data registries, and other best practices.
DVC also supports multiple advanced features out-of-the-box: Build, run, and versioning data pipelines, manage experiments effectively, and more.
Let’s take a closer look at how DVC works in the next chapter with a machine learning experiment example.