
Chapter 3 : Versioning large datasets with DVC#
In the previous chapter, we saw how to install and use DVC to version code and data in a simple way. However, our input dataset was extremely simple and could have been versionned with Git without difficulty.
The main objective of this second chapter is to show the true power of DVC.
We will keep our objective of predicting Alzheimer’s disease (AD) vs Control subjects, but instead of assuming a simple preprocessed dataset with the hippocampus volumes already computed, we will work directly with brain images and train a deep learning model to perform this task.
This chapter also aims at showing some more advanced features of DVC like data pipelines.
We will define our experiment as a pipeline using DVC commands, and see how easily we can reproduce past experiments with this infrastructure.
Let’s dive in !
Install dependencies#
Virtual environments
We strongly encourage you to create a virtual environment specifically for this tutorial. If you haven’t done it already and if you are using conda, you can do the following:
$ conda create --name now python=3.10
$ conda activate now
In order to focus on the code and data management side of things, we abstracted as much code as possible. To do so, we created a very small Python library called now_2023 that we will use in order to plot brain images, train deep learning models, and save results.
If you are running this notebook on Collab, then you need to install it:
# ! pip install now-2023
# If you are running on collab or if you don't have tree installed:
# ! apt-get install tree
! pip install dvc
Collecting dvc
Using cached dvc-3.30.1-py3-none-any.whl.metadata (17 kB)
Collecting colorama>=0.3.9 (from dvc)
Using cached colorama-0.4.6-py2.py3-none-any.whl (25 kB)
Collecting configobj>=5.0.6 (from dvc)
Using cached configobj-5.0.8-py2.py3-none-any.whl (36 kB)
Collecting distro>=1.3 (from dvc)
Using cached distro-1.8.0-py3-none-any.whl (20 kB)
Collecting dpath<3,>=2.1.0 (from dvc)
Using cached dpath-2.1.6-py3-none-any.whl.metadata (15 kB)
Collecting dvc-data<2.23.0,>=2.22.0 (from dvc)
Using cached dvc_data-2.22.0-py3-none-any.whl.metadata (5.3 kB)
Collecting dvc-http>=2.29.0 (from dvc)
Using cached dvc_http-2.30.2-py3-none-any.whl (12 kB)
Collecting dvc-render<1,>=0.3.1 (from dvc)
Using cached dvc_render-0.6.0-py3-none-any.whl.metadata (6.4 kB)
Collecting dvc-studio-client<1,>=0.13.0 (from dvc)
Using cached dvc_studio_client-0.15.0-py3-none-any.whl.metadata (4.3 kB)
Collecting dvc-task<1,>=0.3.0 (from dvc)
Using cached dvc_task-0.3.0-py3-none-any.whl.metadata (10 kB)
Collecting flatten-dict<1,>=0.4.1 (from dvc)
Using cached flatten_dict-0.4.2-py2.py3-none-any.whl (9.7 kB)
Collecting flufl.lock<8,>=5 (from dvc)
Using cached flufl.lock-7.1.1-py3-none-any.whl (11 kB)
Collecting funcy>=1.14 (from dvc)
Using cached funcy-2.0-py2.py3-none-any.whl (30 kB)
Collecting grandalf<1,>=0.7 (from dvc)
Using cached grandalf-0.8-py3-none-any.whl (41 kB)
Collecting gto<2,>=1.4.0 (from dvc)
Using cached gto-1.5.0-py3-none-any.whl.metadata (4.3 kB)
Collecting hydra-core>=1.1 (from dvc)
Using cached hydra_core-1.3.2-py3-none-any.whl (154 kB)
Collecting iterative-telemetry>=0.0.7 (from dvc)
Using cached iterative_telemetry-0.0.8-py3-none-any.whl (10 kB)
Requirement already satisfied: networkx>=2.5 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (3.2.1)
Requirement already satisfied: packaging>=19 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (23.1)
Collecting pathspec>=0.10.3 (from dvc)
Using cached pathspec-0.11.2-py3-none-any.whl.metadata (19 kB)
Requirement already satisfied: platformdirs<4,>=3.1.1 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (3.10.0)
Requirement already satisfied: psutil>=5.8 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (5.9.0)
Collecting pydot>=1.2.4 (from dvc)
Using cached pydot-1.4.2-py2.py3-none-any.whl (21 kB)
Collecting pygtrie>=2.3.2 (from dvc)
Using cached pygtrie-2.5.0-py3-none-any.whl (25 kB)
Requirement already satisfied: pyparsing>=2.4.7 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (3.1.1)
Requirement already satisfied: requests>=2.22 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (2.31.0)
Collecting rich>=12 (from dvc)
Using cached rich-13.7.0-py3-none-any.whl.metadata (18 kB)
Collecting ruamel.yaml>=0.17.11 (from dvc)
Using cached ruamel.yaml-0.18.5-py3-none-any.whl.metadata (23 kB)
Collecting scmrepo<2,>=1.4.1 (from dvc)
Using cached scmrepo-1.4.1-py3-none-any.whl.metadata (5.5 kB)
Collecting shortuuid>=0.5 (from dvc)
Using cached shortuuid-1.0.11-py3-none-any.whl (10 kB)
Collecting shtab<2,>=1.3.4 (from dvc)
Using cached shtab-1.6.4-py3-none-any.whl.metadata (7.3 kB)
Requirement already satisfied: tabulate>=0.8.7 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc) (0.9.0)
Collecting tomlkit>=0.11.1 (from dvc)
Using cached tomlkit-0.12.3-py3-none-any.whl.metadata (2.7 kB)
Collecting tqdm<5,>=4.63.1 (from dvc)
Using cached tqdm-4.66.1-py3-none-any.whl.metadata (57 kB)
Collecting voluptuous>=0.11.7 (from dvc)
Using cached voluptuous-0.14.1-py3-none-any.whl.metadata (20 kB)
Collecting zc.lockfile>=1.2.1 (from dvc)
Using cached zc.lockfile-3.0.post1-py3-none-any.whl (9.8 kB)
Requirement already satisfied: six in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from configobj>=5.0.6->dvc) (1.16.0)
Collecting dictdiffer>=0.8.1 (from dvc-data<2.23.0,>=2.22.0->dvc)
Using cached dictdiffer-0.9.0-py2.py3-none-any.whl (16 kB)
Collecting dvc-objects<2,>=1.1.0 (from dvc-data<2.23.0,>=2.22.0->dvc)
Using cached dvc_objects-1.2.0-py3-none-any.whl.metadata (4.0 kB)
Collecting diskcache>=5.2.1 (from dvc-data<2.23.0,>=2.22.0->dvc)
Using cached diskcache-5.6.3-py3-none-any.whl.metadata (20 kB)
Requirement already satisfied: attrs>=21.3.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc-data<2.23.0,>=2.22.0->dvc) (23.1.0)
Collecting sqltrie<1,>=0.8.0 (from dvc-data<2.23.0,>=2.22.0->dvc)
Using cached sqltrie-0.8.0-py3-none-any.whl.metadata (3.7 kB)
Requirement already satisfied: fsspec[http] in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from dvc-http>=2.29.0->dvc) (2023.10.0)
Collecting aiohttp-retry>=2.5.0 (from dvc-http>=2.29.0->dvc)
Using cached aiohttp_retry-2.8.3-py3-none-any.whl (9.8 kB)
Collecting dulwich (from dvc-studio-client<1,>=0.13.0->dvc)
Using cached dulwich-0.21.6-cp310-cp310-macosx_10_9_x86_64.whl.metadata (4.3 kB)
Collecting celery<6,>=5.3.0 (from dvc-task<1,>=0.3.0->dvc)
Using cached celery-5.3.5-py3-none-any.whl.metadata (21 kB)
Collecting kombu<6,>=5.3.0 (from dvc-task<1,>=0.3.0->dvc)
Using cached kombu-5.3.4-py3-none-any.whl.metadata (3.1 kB)
Collecting atpublic>=2.3 (from flufl.lock<8,>=5->dvc)
Using cached atpublic-4.0-py3-none-any.whl.metadata (1.8 kB)
Collecting typer>=0.4.1 (from gto<2,>=1.4.0->dvc)
Using cached typer-0.9.0-py3-none-any.whl (45 kB)
Collecting pydantic!=2.0.0,<3,>=1.9.0 (from gto<2,>=1.4.0->dvc)
Using cached pydantic-2.5.1-py3-none-any.whl.metadata (64 kB)
Collecting semver>=3.0.0 (from gto<2,>=1.4.0->dvc)
Using cached semver-3.0.2-py3-none-any.whl.metadata (5.0 kB)
Collecting entrypoints (from gto<2,>=1.4.0->dvc)
Using cached entrypoints-0.4-py3-none-any.whl (5.3 kB)
Collecting omegaconf<2.4,>=2.2 (from hydra-core>=1.1->dvc)
Using cached omegaconf-2.3.0-py3-none-any.whl (79 kB)
Collecting antlr4-python3-runtime==4.9.* (from hydra-core>=1.1->dvc)
Using cached antlr4_python3_runtime-4.9.3-py3-none-any.whl
Collecting appdirs (from iterative-telemetry>=0.0.7->dvc)
Using cached appdirs-1.4.4-py2.py3-none-any.whl (9.6 kB)
Requirement already satisfied: filelock in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from iterative-telemetry>=0.0.7->dvc) (3.13.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from requests>=2.22->dvc) (2.0.4)
Requirement already satisfied: idna<4,>=2.5 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from requests>=2.22->dvc) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from requests>=2.22->dvc) (1.26.18)
Requirement already satisfied: certifi>=2017.4.17 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from requests>=2.22->dvc) (2023.7.22)
Requirement already satisfied: markdown-it-py>=2.2.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from rich>=12->dvc) (2.2.0)
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from rich>=12->dvc) (2.15.1)
Collecting ruamel.yaml.clib>=0.2.7 (from ruamel.yaml>=0.17.11->dvc)
Using cached ruamel.yaml.clib-0.2.8-cp310-cp310-macosx_10_9_universal2.whl.metadata (2.2 kB)
Collecting gitpython>3 (from scmrepo<2,>=1.4.1->dvc)
Using cached GitPython-3.1.40-py3-none-any.whl.metadata (12 kB)
Collecting pygit2>=1.13.0 (from scmrepo<2,>=1.4.1->dvc)
Using cached pygit2-1.13.2-cp310-cp310-macosx_10_9_universal2.whl.metadata (3.6 kB)
Collecting asyncssh<3,>=2.13.1 (from scmrepo<2,>=1.4.1->dvc)
Using cached asyncssh-2.14.1-py3-none-any.whl.metadata (9.9 kB)
Requirement already satisfied: setuptools in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from zc.lockfile>=1.2.1->dvc) (68.0.0)
Collecting aiohttp (from aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached aiohttp-3.9.0-cp310-cp310-macosx_10_9_x86_64.whl.metadata (7.4 kB)
Requirement already satisfied: cryptography>=39.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from asyncssh<3,>=2.13.1->scmrepo<2,>=1.4.1->dvc) (41.0.3)
Requirement already satisfied: typing-extensions>=3.6 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from asyncssh<3,>=2.13.1->scmrepo<2,>=1.4.1->dvc) (4.7.1)
Collecting billiard<5.0,>=4.2.0 (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached billiard-4.2.0-py3-none-any.whl.metadata (4.4 kB)
Collecting click-didyoumean>=0.3.0 (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached click_didyoumean-0.3.0-py3-none-any.whl (2.7 kB)
Collecting click-plugins>=1.1.1 (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached click_plugins-1.1.1-py2.py3-none-any.whl (7.5 kB)
Collecting click-repl>=0.2.0 (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached click_repl-0.3.0-py3-none-any.whl.metadata (3.6 kB)
Requirement already satisfied: click<9.0,>=8.1.2 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc) (8.1.7)
Requirement already satisfied: python-dateutil>=2.8.2 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc) (2.8.2)
Requirement already satisfied: tzdata>=2022.7 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc) (2023.3)
Collecting vine<6.0,>=5.1.0 (from celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached vine-5.1.0-py3-none-any.whl.metadata (2.7 kB)
Collecting gitdb<5,>=4.0.1 (from gitpython>3->scmrepo<2,>=1.4.1->dvc)
Using cached gitdb-4.0.11-py3-none-any.whl.metadata (1.2 kB)
Collecting amqp<6.0.0,>=5.1.1 (from kombu<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc)
Using cached amqp-5.2.0-py3-none-any.whl.metadata (8.9 kB)
Requirement already satisfied: mdurl~=0.1 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from markdown-it-py>=2.2.0->rich>=12->dvc) (0.1.2)
Requirement already satisfied: PyYAML>=5.1.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from omegaconf<2.4,>=2.2->hydra-core>=1.1->dvc) (6.0.1)
Collecting annotated-types>=0.4.0 (from pydantic!=2.0.0,<3,>=1.9.0->gto<2,>=1.4.0->dvc)
Using cached annotated_types-0.6.0-py3-none-any.whl.metadata (12 kB)
Collecting pydantic-core==2.14.3 (from pydantic!=2.0.0,<3,>=1.9.0->gto<2,>=1.4.0->dvc)
Using cached pydantic_core-2.14.3-cp310-cp310-macosx_10_7_x86_64.whl.metadata (6.5 kB)
Requirement already satisfied: cffi>=1.16.0 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from pygit2>=1.13.0->scmrepo<2,>=1.4.1->dvc) (1.16.0)
Collecting orjson (from sqltrie<1,>=0.8.0->dvc-data<2.23.0,>=2.22.0->dvc)
Using cached orjson-3.9.10-cp310-cp310-macosx_10_15_x86_64.macosx_11_0_arm64.macosx_10_15_universal2.whl.metadata (49 kB)
Collecting multidict<7.0,>=4.5 (from aiohttp->aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached multidict-6.0.4-cp310-cp310-macosx_10_9_x86_64.whl (29 kB)
Collecting yarl<2.0,>=1.0 (from aiohttp->aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached yarl-1.9.2-cp310-cp310-macosx_10_9_x86_64.whl (65 kB)
Collecting frozenlist>=1.1.1 (from aiohttp->aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached frozenlist-1.4.0-cp310-cp310-macosx_10_9_x86_64.whl.metadata (5.2 kB)
Collecting aiosignal>=1.1.2 (from aiohttp->aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached aiosignal-1.3.1-py3-none-any.whl (7.6 kB)
Collecting async-timeout<5.0,>=4.0 (from aiohttp->aiohttp-retry>=2.5.0->dvc-http>=2.29.0->dvc)
Using cached async_timeout-4.0.3-py3-none-any.whl.metadata (4.2 kB)
Requirement already satisfied: pycparser in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from cffi>=1.16.0->pygit2>=1.13.0->scmrepo<2,>=1.4.1->dvc) (2.21)
Requirement already satisfied: prompt-toolkit>=3.0.36 in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from click-repl>=0.2.0->celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc) (3.0.36)
Collecting smmap<6,>=3.0.1 (from gitdb<5,>=4.0.1->gitpython>3->scmrepo<2,>=1.4.1->dvc)
Using cached smmap-5.0.1-py3-none-any.whl.metadata (4.3 kB)
Requirement already satisfied: wcwidth in /Users/nicolas.gensollen/opt/anaconda3/envs/now/lib/python3.10/site-packages (from prompt-toolkit>=3.0.36->click-repl>=0.2.0->celery<6,>=5.3.0->dvc-task<1,>=0.3.0->dvc) (0.2.5)
Using cached dvc-3.30.1-py3-none-any.whl (430 kB)
Using cached dpath-2.1.6-py3-none-any.whl (17 kB)
Using cached dvc_data-2.22.0-py3-none-any.whl (68 kB)
Using cached dvc_render-0.6.0-py3-none-any.whl (19 kB)
Using cached dvc_studio_client-0.15.0-py3-none-any.whl (13 kB)
Using cached dvc_task-0.3.0-py3-none-any.whl (21 kB)
Using cached gto-1.5.0-py3-none-any.whl (46 kB)
Using cached pathspec-0.11.2-py3-none-any.whl (29 kB)
Using cached rich-13.7.0-py3-none-any.whl (240 kB)
Using cached ruamel.yaml-0.18.5-py3-none-any.whl (116 kB)
Using cached scmrepo-1.4.1-py3-none-any.whl (58 kB)
Using cached shtab-1.6.4-py3-none-any.whl (13 kB)
Using cached tomlkit-0.12.3-py3-none-any.whl (37 kB)
Using cached tqdm-4.66.1-py3-none-any.whl (78 kB)
Using cached voluptuous-0.14.1-py3-none-any.whl (30 kB)
Using cached asyncssh-2.14.1-py3-none-any.whl (352 kB)
Using cached atpublic-4.0-py3-none-any.whl (4.9 kB)
Using cached celery-5.3.5-py3-none-any.whl (421 kB)
Using cached diskcache-5.6.3-py3-none-any.whl (45 kB)
Using cached dulwich-0.21.6-cp310-cp310-macosx_10_9_x86_64.whl (472 kB)
Using cached dvc_objects-1.2.0-py3-none-any.whl (38 kB)
Using cached GitPython-3.1.40-py3-none-any.whl (190 kB)
Using cached kombu-5.3.4-py3-none-any.whl (199 kB)
Using cached pydantic-2.5.1-py3-none-any.whl (381 kB)
Using cached pydantic_core-2.14.3-cp310-cp310-macosx_10_7_x86_64.whl (1.9 MB)
Using cached pygit2-1.13.2-cp310-cp310-macosx_10_9_universal2.whl (5.8 MB)
Using cached ruamel.yaml.clib-0.2.8-cp310-cp310-macosx_10_9_universal2.whl (148 kB)
Using cached semver-3.0.2-py3-none-any.whl (17 kB)
Using cached sqltrie-0.8.0-py3-none-any.whl (17 kB)
Using cached aiohttp-3.9.0-cp310-cp310-macosx_10_9_x86_64.whl (396 kB)
Using cached amqp-5.2.0-py3-none-any.whl (50 kB)
Using cached annotated_types-0.6.0-py3-none-any.whl (12 kB)
Using cached billiard-4.2.0-py3-none-any.whl (86 kB)
Using cached click_repl-0.3.0-py3-none-any.whl (10 kB)
Using cached gitdb-4.0.11-py3-none-any.whl (62 kB)
Using cached vine-5.1.0-py3-none-any.whl (9.6 kB)
Using cached orjson-3.9.10-cp310-cp310-macosx_10_15_x86_64.macosx_11_0_arm64.macosx_10_15_universal2.whl (242 kB)
Using cached async_timeout-4.0.3-py3-none-any.whl (5.7 kB)
Using cached frozenlist-1.4.0-cp310-cp310-macosx_10_9_x86_64.whl (46 kB)
Using cached smmap-5.0.1-py3-none-any.whl (24 kB)
Installing collected packages: pygtrie, funcy, dictdiffer, appdirs, antlr4-python3-runtime, zc.lockfile, voluptuous, vine, typer, tqdm, tomlkit, smmap, shtab, shortuuid, semver, ruamel.yaml.clib, pydot, pydantic-core, pathspec, orjson, omegaconf, multidict, grandalf, frozenlist, flatten-dict, entrypoints, dvc-render, dulwich, dpath, distro, diskcache, configobj, colorama, click-plugins, click-didyoumean, billiard, atpublic, async-timeout, annotated-types, yarl, sqltrie, ruamel.yaml, rich, pygit2, pydantic, iterative-telemetry, hydra-core, gitdb, flufl.lock, dvc-studio-client, dvc-objects, click-repl, amqp, aiosignal, kombu, gitpython, dvc-data, asyncssh, aiohttp, scmrepo, celery, aiohttp-retry, gto, dvc-task, dvc-http, dvc
Successfully installed aiohttp-3.9.0 aiohttp-retry-2.8.3 aiosignal-1.3.1 amqp-5.2.0 annotated-types-0.6.0 antlr4-python3-runtime-4.9.3 appdirs-1.4.4 async-timeout-4.0.3 asyncssh-2.14.1 atpublic-4.0 billiard-4.2.0 celery-5.3.5 click-didyoumean-0.3.0 click-plugins-1.1.1 click-repl-0.3.0 colorama-0.4.6 configobj-5.0.8 dictdiffer-0.9.0 diskcache-5.6.3 distro-1.8.0 dpath-2.1.6 dulwich-0.21.6 dvc-3.30.1 dvc-data-2.22.0 dvc-http-2.30.2 dvc-objects-1.2.0 dvc-render-0.6.0 dvc-studio-client-0.15.0 dvc-task-0.3.0 entrypoints-0.4 flatten-dict-0.4.2 flufl.lock-7.1.1 frozenlist-1.4.0 funcy-2.0 gitdb-4.0.11 gitpython-3.1.40 grandalf-0.8 gto-1.5.0 hydra-core-1.3.2 iterative-telemetry-0.0.8 kombu-5.3.4 multidict-6.0.4 omegaconf-2.3.0 orjson-3.9.10 pathspec-0.11.2 pydantic-2.5.1 pydantic-core-2.14.3 pydot-1.4.2 pygit2-1.13.2 pygtrie-2.5.0 rich-13.7.0 ruamel.yaml-0.18.5 ruamel.yaml.clib-0.2.8 scmrepo-1.4.1 semver-3.0.2 shortuuid-1.0.11 shtab-1.6.4 smmap-5.0.1 sqltrie-0.8.0 tomlkit-0.12.3 tqdm-4.66.1 typer-0.9.0 vine-5.1.0 voluptuous-0.14.1 yarl-1.9.2 zc.lockfile-3.0.post1
Setup the repo#
Since this is a new notebook meant to be independant from the notebooks of the first chapters, we will start a new project from scratch.
Start by configuring the Git and DVC repo.
Warning
If you are running this notebook on Collab, or if you are using an old version of Git, you need to run the following cell which will make sure your default branch is nammed main and not master as this default was changed a couple years ago.
Otherwise, you would have to change main to master manually in all the commands of this notebook.
! git config --global init.defaultBranch main
! git init
! dvc init
Initialized empty Git repository in /Users/nicolas.gensollen/GitRepos/NOW-2023/notebooks/.git/
Initialized DVC repository.
You can now commit the changes to git.
+---------------------------------------------------------------------+
| |
| DVC has enabled anonymous aggregate usage analytics. |
| Read the analytics documentation (and how to opt-out) here: |
| <https://dvc.org/doc/user-guide/analytics> |
| |
+---------------------------------------------------------------------+
What's next?
------------
- Check out the documentation: <https://dvc.org/doc>
- Get help and share ideas: <https://dvc.org/chat>
- Star us on GitHub: <https://github.com/iterative/dvc>
As with the previous notebook, you might need to configure your username and email:
! git config --local user.email "john.doe@inria.fr"
! git config --local user.name "John Doe"
! git commit -m "initialize DVC"
[main (root-commit) 9e911d6] initialize DVC
3 files changed, 6 insertions(+)
create mode 100644 .dvc/.gitignore
create mode 100644 .dvc/config
create mode 100644 .dvcignore
Note
Throughout this tutorial, we will write things to files. Usually, you would do this using your favorite IDE. However, we need this tutorial to be runnable as a notebook (for example for the attendees running it on Collab). Because of this, we will be using IPython magic commands %%writefile and %run in order to write to a file the content of a cell, and run a given python script.
If you are following locally, you can of course edit the different files directly !
Let’s add some patterns to the .gitignore file in order to not display IPython notebooks related files when doing a git status:
%%writefile -a .gitignore
*.ipynb
__pycache__
.DS_Store
.ipynb_checkpoints
.config
OASIS-1-dataset*
sample_data
Writing .gitignore
Getting the input dataset#
In this session we use the images from a public research project: OASIS-1. Two labels exist in this dataset:
CN (Cognitively Normal) for healthy participants.
AD (Alzheimer’s Disease) for patients affected by Alzheimer’s disease.
The original images were preprocessed using Clinica: a software platform for clinical neuroimaging studies.
Preprocessed images and other files are distributed in a tarball, if you haven’t downloaded the images before the tutorial, run the following commands to download and extract them:
# Only run if necessary !
#
# ! wget --no-check-certificate --show-progress https://aramislab.paris.inria.fr/files/data/databases/DL4MI/OASIS-1-dataset_pt_new.tar.gz
# ! tar -xzf OASIS-1-dataset_pt_new.tar.gz
Write a Python script to run the experiment#
Let’s start writing a Python file which will contain the code required to train our model. Our objective is to be able to run
$ python train.py
from the command-line to train our model on our input dataset.
We are going to progressively add things to this file in order to fullfil this goal.
Let’s start by defining the path to the raw dataset folder we just downloaded. If you run the cell above, it should be ./OASIS-1_dataset. If you downloaded the data before the workshop, it is probably somewhere else on your machine.
%%writefile -a train.py
from pathlib import Path
# If you just downloaded the data using the cell above, then uncomment:
#
# oasis_folder = Path("./OASIS-1_dataset/")
#
# Otherwise, modify this path to the folder in which you extracted the data:
#
oasis_folder = Path("/Users/nicolas.gensollen/NOW_2023/OASIS-1_dataset/")
Writing train.py
Executing the previous cell wrote its content to our file, let’s also execute this file to have the declared imports and variables in this Python session:
%run train.py
print([file.name for file in oasis_folder.iterdir()])
['CAPS', 'README.md', 'tsv_files', 'raw']
The raw dataset contains:
a
tsv_filesfolder in which we have metadata relative to the different subjectsa
README.mdfile giving some information on the dataseta
CAPSfolder holding the preprocessed brain imagesa
rawfolder holding the raw brain images
At the same time, we will write a second Python file prepare_train_validation_sets.py which will be responsible for splitting our list of subjects into a training set and a validation set. This is important because we will compute validation metrics once our model has been trained:
%%writefile -a prepare_train_validation_sets.py
import pandas as pd
from pathlib import Path
# oasis_folder = Path("./OASIS-1_dataset/")
oasis_folder = Path("/Users/nicolas.gensollen/NOW_2023/OASIS-1_dataset/")
columns_to_use = [
"participant_id",
"session_id",
"alternative_id_1",
"sex",
"education_level",
"age_bl",
"diagnosis_bl",
"laterality",
"MMS",
"cdr_global",
"diagnosis",
]
OASIS_df = pd.read_csv(
oasis_folder / "tsv_files" / "lab_1" / "OASIS_BIDS.tsv",
sep="\t",
usecols=columns_to_use,
)
Writing prepare_train_validation_sets.py
%run prepare_train_validation_sets.py
Let’s take a look at some statistics in order to better understand our data:
print(OASIS_df.head())
_ = OASIS_df.hist(figsize=(16, 8))
participant_id session_id alternative_id_1 sex education_level age_bl \
0 sub-OASIS10001 ses-M00 OAS1_0001_MR1 F 2.0 74
1 sub-OASIS10002 ses-M00 OAS1_0002_MR1 F 4.0 55
2 sub-OASIS10003 ses-M00 OAS1_0003_MR1 F 4.0 73
3 sub-OASIS10004 ses-M00 OAS1_0004_MR1 M NaN 28
4 sub-OASIS10005 ses-M00 OAS1_0005_MR1 M NaN 18
diagnosis_bl laterality MMS cdr_global diagnosis
0 CN R 29.0 0.0 CN
1 CN R 29.0 0.0 CN
2 AD R 27.0 0.5 AD
3 CN R 30.0 NaN CN
4 CN R 30.0 NaN CN
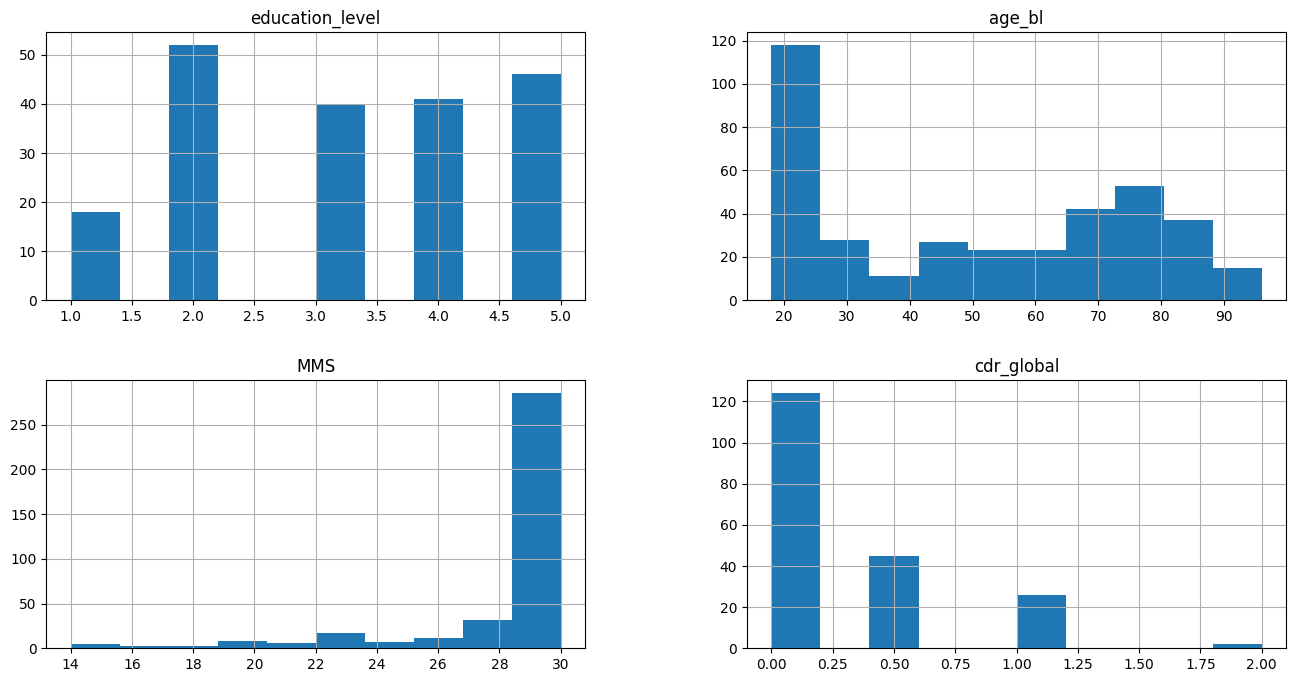
From these graphics, it’s possible to have an overview of the distribution of the data, for the numerical values. For example, the educational level is well distributed among the participants of the study. Also, most of the subjects are young (around 20 years old) and healthy (MMS score equals 30 and null CDR score).
We can use the characteristics_table function from now-2023 to get some useful statistics at the population level:
from now_2023.utils import characteristics_table
population_df = characteristics_table(OASIS_df, OASIS_df)
population_df
| N | age | %sexF | education | MMS | CDR=0 | CDR=0.5 | CDR=1 | CDR=2 | |
|---|---|---|---|---|---|---|---|---|---|
| AD | 73 | 77.5 ± 7.4 | 63.0 | 2.7 ± 1.3 | 22.7 ± 3.6 | 0 | 45 | 26 | 2 |
| CN | 304 | 44.0 ± 23.3 | 62.2 | 3.5 ± 1.2 | 29.7 ± 0.6 | 124 | 0 | 0 | 0 |
Preprocessing#
Theoretically, the main advantage of deep learning methods is to be able to work without extensive data preprocessing. However, as we have only a few images to train the network in this lab session, the preprocessing here is very extensive. More specifically, the images encountered:
Non-linear registration.
Segmentation of grey matter.
Conversion to tensor format (.pt).
As mentioned above, to obtain the preprocessed images, we used some pipelines provided by Clinica and ClinicaDL in order to:
Convert the original dataset to BIDS format (clinica convert oasis-2-bids).
Get the non-linear registration and segmentation of grey mater (pipeline t1-volume).
Obtain the preprocessed images in tensor format (tensor extraction using ClinicaDL, clinicadl extract).
The preprocessed images are store in the CAPS folder structure and all have the same size (121x145x121).
To facilitate the training and avoid overfitting due to the limited amount of data, the model won’t use the full image but only a part of the image (size 30x40x30) centered on a specific neuroanatomical region: the hippocampus (HC). This structure is known to be linked to memory, and is atrophied in the majority of cases of Alzheimer’s disease patients.
Before going further, let’s take a look at the images we have downloaded and let’s compute a cropped image of the left HC for a randomly selected subject:
import torch
# Select a random subject
subject = 'sub-OASIS10003'
# The path to the hc image
image_folder = (
oasis_folder /
"CAPS" /
"subjects" /
subject /
"ses-M00" /
"deeplearning_prepare_data" /
"image_based" /
"custom"
)
# The image file name as a specific structure
image_filename = f"{subject}_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability.pt"
preprocessed_pt = torch.load(image_folder / image_filename)
You can use the CropLeftHC class to automatically crop the left HC from the preprocessed tensor images. You can also use plot_image and plot_tensor functions from the now-2023 library to visualize these images.
View different slices
Do not hesitate to play with the cut_coords argument to view different slices!
from now_2023.plotting import plot_image, plot_tensor
from now_2023.utils import CropLeftHC
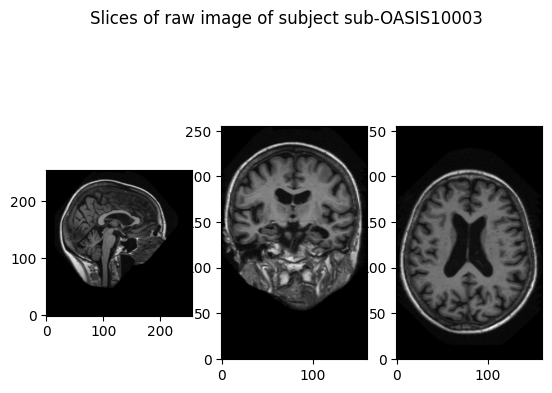
plot_image(
oasis_folder / "raw" / f"{subject}_ses-M00_T1w.nii.gz",
cut_coords=(78, 122, 173),
title=f'Slices of raw image of subject {subject}',
)
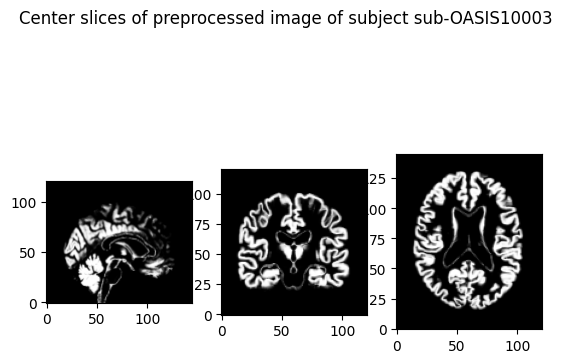
plot_tensor(
preprocessed_pt,
cut_coords=(60, 72, 60),
title=f'Center slices of preprocessed image of subject {subject}',
)
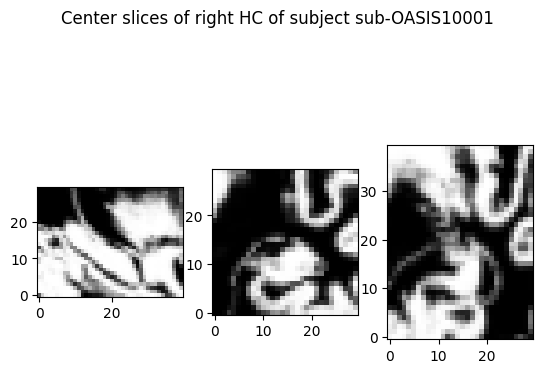
plot_tensor(
CropLeftHC()(preprocessed_pt),
cut_coords=(15, 20, 15),
title=f'Center slices of left HC of subject {subject}',
)

Use only the left HC#
We are going to generate a new dataset consisting only of images of the left hippocampus. Our dataset will basically consist of images like the last image above.
For simplicity, this is the dataset that we will consider as our input dataset, just like we pretended that the TSV file with the HC volumes computed was our input dataset in the previous chapter. This also means that the dataset we are about to generate will be the one we will version.
Note
Note that there is nothing preventing us to version the raw dataset. We are doing this because we will pretend to receive a data update later on consisting of the right HC images.
Note also that to improve the training and reduce overfitting, we can add a random shift to the cropping function. This means that the bounding box around the hippocampus may be shifted by a limited amount of voxels in each of the three directions.
Let’s generate our dataset with the generate_cropped_hc_dataset function from the now-2023 library.
from now_2023.data_generation import generate_cropped_hc_dataset
data_folder = Path("./data")
generate_cropped_hc_dataset(
oasis_folder,
hemi="left",
output_folder=data_folder,
verbose=False,
)
This should have created a new data folder in the current workspace, which should have the following structure:
! tree data | head -n 14
data
└── subjects
├── sub-OASIS10001
│ └── ses-M00
│ └── deeplearning_prepare_data
│ └── image_based
│ └── custom
│ └── sub-OASIS10001_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_left.pt
├── sub-OASIS10002
│ └── ses-M00
│ └── deeplearning_prepare_data
│ └── image_based
│ └── custom
│ └── sub-OASIS10002_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_left.pt
As you can see, we have one tensor image for each subject, representing the extracted left hippocampus.
Let’s take a look at some of these images. To do so, you can use the plot_hc function from the now-2023 library which is a wrapper around the plot_tensor function you used before.
Again, feel free to play with the parameters to view different slices or different subjects:
from now_2023.plotting import plot_hc
plot_hc(data_folder, 'sub-OASIS10001', "left", cut_coords=(15, 20, 15))
plot_hc(data_folder, 'sub-OASIS10003', "left", cut_coords=(10, 30, 25))


Cross-validation#
In order to choose hyperparameters the set of images is divided into a training set (80%) and a validation set (20%). The data split was performed in order to ensure a similar distribution of diagnosis, age and sex between the subjects of the training set and the subjects of the validation set. Moreover the MMS distribution of each class is preserved.
%%writefile -a prepare_train_validation_sets.py
from now_2023.utils import characteristics_table
train_df = pd.read_csv(oasis_folder / "tsv_files" / "lab_1" / "train.tsv", sep="\t")
valid_df = pd.read_csv(oasis_folder / "tsv_files" / "lab_1" / "validation.tsv", sep="\t")
train_df["hemi"] = "left"
valid_df["hemi"] = "left"
train_population_df = characteristics_table(train_df, OASIS_df)
valid_population_df = characteristics_table(valid_df, OASIS_df)
print("*" * 50)
print(f"Train dataset:\n {train_population_df}\n")
print("*" * 50)
print(f"Validation dataset:\n {valid_population_df}")
print("*" * 50)
train_df.to_csv("train.csv")
valid_df.to_csv("validation.csv")
Appending to prepare_train_validation_sets.py
At this point, the step of our experiment consisting of preparing the training and validation sets is complete. We could simply run
python prepare_train_validation_sets.py
but we are going to see another way to do that. Instead of just running this command, we are going to use DVC to codify our first experimental step. To do that, we will rely on the dvc stage comand which is a bit more complicated than the previous DVC commands we saw before:
! dvc stage add -n prepare_train_validation \
-d prepare_train_validation_sets.py -d data \
-o train.csv -o validation.csv \
python prepare_train_validation_sets.py
Added stage 'prepare_train_validation' in 'dvc.yaml' core>
To track the changes with git, run:
git add .gitignore dvc.yaml
To enable auto staging, run:
dvc config core.autostage true
Let’s take a closer look at this long command:
The
-noption enables us to give a name to this step. In our case, we named it “prepare_train_validation”.The
-doption enables us to declare dependencies, that is things on which this step depends. In our case, the step depends on the input data (thedatafolder), and the python file itself (prepare_train_validation_sets.py).The
-ooption enables ut to declare outputs, that is things that are produced by this step. In our case, the step produces two CSV files (train.csvandvalidation.csv)The final part of the command tells DVC the command it should run to perform this step. In our case, it needs to run
python prepare_train_validation_sets.pyto run the Python script.
OK, great, but what did this command actually do ?
As you can see from its output, it generated a dvc.yaml file which encode our experiment stage as well as its dependencies. Let’s have a look at it:
! cat dvc.yaml
stages:
prepare_train_validation:
cmd: python prepare_train_validation_sets.py
deps:
- data
- prepare_train_validation_sets.py
outs:
- train.csv
- validation.csv
As you can see, it is pretty easy to read and understand. There is nothing more than what we just described above.
However, dvc stage didn’t run anything, it just generated this file. To run our first step, we can use the dvc repro command:
! dvc repro
Running stage 'prepare_train_validation':
> python prepare_train_validation_sets.py
**************************************************
Train dataset:
N age %sexF education MMS CDR=0 CDR=0.5 CDR=1 CDR=2
AD 58 77.4 ± 7.5 69.0 2.8 ± 1.4 22.6 ± 3.6 0 37 19 2
CN 242 43.4 ± 23.5 62.0 3.6 ± 1.2 29.8 ± 0.5 97 0 0 0
**************************************************
Validation dataset:
N age %sexF education MMS CDR=0 CDR=0.5 CDR=1 CDR=2
AD 15 78.2 ± 6.6 40.0 2.5 ± 1.0 22.9 ± 3.6 0 8 7 0
CN 62 46.3 ± 22.6 62.9 3.4 ± 1.3 29.6 ± 0.7 27 0 0 0
**************************************************
Generating lock file 'dvc.lock'
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
In the output of dvc repro we can see the output generated by our Python scripts as well as the output generated by DVC.
It looks like DVC generated a dvc.lock file:
! cat dvc.lock
schema: '2.0'
stages:
prepare_train_validation:
cmd: python prepare_train_validation_sets.py
deps:
- path: data
hash: md5
md5: 95c25bee3697aa6cae552468a24896ec.dir
size: 60729344
nfiles: 416
- path: prepare_train_validation_sets.py
hash: md5
md5: c8015ec57c1b76bd7578e0e8e6a41422
size: 1139
outs:
- path: train.csv
hash: md5
md5: a696d40de31a824be7f8376404da00df
size: 10432
- path: validation.csv
hash: md5
md5: aa08487b3f7ec7c367d9a4c1dba20158
size: 2650
We won’t go into the details here, but the main idea is that this lock file is what DVC uses to know whether it should re-run a given stage given the state of the current workspace. It basically does this by computing the hash values of the stage dependencies and outputs and comparing these values to the ones in this file. If there is at least one mismatch, then the stage should be run again, otherwise DVC will use the cached inputs and outputs.
Note that these new files (dvc.yaml and dvc.lock) are still very small files which size does not depend on the input data size. This means that we are totally fine versioning them with Git, and this is precisely what DVC is telling us to do here.
Let’s add the data with dvc add (we still haven’t done that…), and do the same with Git for the files we have generated (dvc.yaml, dvc.lock, data.dvc), and modified (.gitignore):
! dvc add data
! git add dvc.yaml .gitignore dvc.lock data.dvc
?25l core>⠋ Checking graph
Adding...
!
Collecting files and computing hashes in data |0.00 [00:00, ?file/s]
Collecting files and computing hashes in data |123 [00:00, 1.22kfile/s]
Collecting files and computing hashes in data |274 [00:00, 1.39kfile/s]
!
0% Checking cache in '/Users/nicolas.gensollen/GitRepos/NOW-2023/notebooks/.dv
!
0%| |Adding data to cache 0/? [00:00<?, ?file/s]
0%| |Adding data to cache 0/416 [00:00<?, ?file/s]
0%| |Adding data to cache 0/416 [00:00<?, ?file/s]
70%|██████▉ |Adding data to cache 290/416 [00:00<00:00, 2886.46file/s]
!
0%| |Checking out /Users/nicolas.gensollen/0/? [00:00<?, ?files/s]
0%| |Checking out /Users/nicolas.gensolle0/417 [00:00<?, ?files/s]
33%|███▎ |Checking out /Users/nicolas139/417 [00:00<00:00, 1383.13files/s]
67%|██████▋ |Checking out /Users/nicolas278/417 [00:00<00:00, 1338.01files/s]
100% Adding...|████████████████████████████████████████|1/1 [00:01, 1.50s/file]
To track the changes with git, run:
git add data.dvc .gitignore
To enable auto staging, run:
dvc config core.autostage true
! git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: .gitignore
new file: data.dvc
new file: dvc.lock
new file: dvc.yaml
Untracked files:
(use "git add <file>..." to include in what will be committed)
prepare_train_validation_sets.py
train.py
DVC also provides some utilities to visualize the data pipelines as graphs. We can visualize our pipeline with the dvc dag command:
! dvc dag
+----------+
| data.dvc |
+----------+
*
*
*
+--------------------------+
| prepare_train_validation |
+--------------------------+
By default, the dvc dag command returns a simple textual representation of the graph, but there exists various ways to get more complex representation like mermaid flowcharts for example:
! dvc dag --mermaid
flowchart TD
node1["data.dvc"]
node2["prepare_train_validation"]
node1-->node2
Train the model#
We propose here to use a convolutional neural network model to make our prediction. Again, we won’t go into the architectural details of this model as this isn’t the objective of this tutorial. Instead, we will use the CNNModel from the now-2023 library.
The network model requires some hyper-parameters:
the learning_rate
the number of epochs
the batch size
We could just hardcode them in our Python script when instantiating the model but we are going to implement this in a more flexible way. We will see later in this tutorial why it is interresting to define them this way.
DVC enables ut to define parameters in specific YAML files. Let’s create a params.yaml file and define our hyper-parameters in it:
%%writefile -a params.yaml
train:
learning_rate: 0.0001
n_epochs: 30
batch_size: 4
Writing params.yaml
The structure is pretty simple, you define the parameters as key-value pairs and you can either define them all at the root, or organize them in a hierarchical way.
Here we decided to put all the parameters inside a train section, but we could have defined them all at the root as well.
We are now ready to finish our Python script responsible for creating the model, training it, and saving the results. Let’s do this step by step.
First, we need to retrieve the hyper-parameters we just defined in the params.yaml file. We use the DVC Python API to do so.
%%writefile -a train.py
import dvc.api
params = dvc.api.params_show()
# Parameters can be accessed through a dictionnary interface
# We get a nested dict because we defined them within a section named 'train'
learning_rate = params['train']['learning_rate']
n_epochs = params['train']['n_epochs']
batch_size = params['train']['batch_size']
Appending to train.py
Then, we need to load the training and validation sets which are available as two CSV files thanks to the previous step of the pipeline:
%%writefile -a train.py
import pandas as pd
train_df = pd.read_csv("train.csv")
valid_df = pd.read_csv("validation.csv")
Appending to train.py
At this point, we have everything we need to instantiate and train our network model:
%%writefile -a train.py
from now_2023.models import CNNModel
data_folder = Path("./data")
print("*" * 50)
model = CNNModel(
learning_rate=learning_rate,
n_epochs=n_epochs,
batch_size=batch_size,
)
print(f"Fitting model on {len(train_df)} samples...")
model.fit(data_folder, train_df)
Appending to train.py
The only thing left to do is to compute metrics and save our ouptuts to disk. We generate the following outputs:
The model’s weights in
model.h5.The metrics in
metrics.json.A small human-readable note describing what we did in
notes.txt(this could be useful, for example, to your future self revisiting this experiment in a few months or years…).
%%writefile -a train.py
import json
results_training_left, metrics_training_left = model.predict(data_folder, train_df)
results_validation_left, metrics_validation_left = model.predict(data_folder, valid_df)
print("*" * 50)
print(f"Metrics on training set :\n{json.dumps(metrics_training_left, indent=4)}")
print(f"Metrics on validation set :\n{json.dumps(metrics_validation_left, indent=4)}")
print("*" * 50)
model.save("model.h5")
with open("metrics.json", "w") as fp:
json.dump(metrics_validation_left, fp, indent=4)
with open("notes.txt", "w") as fp:
fp.write(
f"CNN model fitted on {len(train_df)} samples with hyperparameters:\n"
f"- learning rate = {learning_rate}\n"
f"- number of epochs = {n_epochs}\n"
f"- size of batch = {batch_size}\n"
)
Appending to train.py
We can now add this new stage to our pipeline with the dvc stage command. As we saw with the previous stage, this command is quite long so we need to think about this stage dependencies and outputs:
First, we will call this stage train_network. Then, this stage requires three parameters (defined in the params.yaml file), and it has four dependencies (the train.py file which is the Python code implementing what needs to be done in this stage, the data folder which contains our input images on which the network is trained, and the two CSV files train.csv and validation.csv which define the training and validation sets).
In addition, it generates two outputs (model.h5 which contains the model’s weights after training, and notes.txt which is our small note), as well as one metric file, metrics.json, that DVC handles in a slightly different way than the other outputs.
Finally, we need to give the command that should be run for executing this stage. In our case, it is simply python train.py.
With this in mind, we can write the dvc stage command:
! dvc stage add -n train_network \
-p train.learning_rate,train.n_epochs,train.batch_size \
-d train.py -d data -d train.csv -d validation.csv \
-o model.h5 -o notes.txt -M metrics.json python train.py
Added stage 'train_network' in 'dvc.yaml' core>
To track the changes with git, run:
git add dvc.yaml .gitignore
To enable auto staging, run:
dvc config core.autostage true
Let’s check the dvc.yaml file which should have been modified:
! cat dvc.yaml
stages:
prepare_train_validation:
cmd: python prepare_train_validation_sets.py
deps:
- data
- prepare_train_validation_sets.py
outs:
- train.csv
- validation.csv
train_network:
cmd: python train.py
deps:
- data
- train.csv
- train.py
- validation.csv
params:
- train.batch_size
- train.learning_rate
- train.n_epochs
outs:
- model.h5
- notes.txt
metrics:
- metrics.json:
cache: false
Great ! The dvc.yaml file has been modified with the new train_network stage we just created. We can see that this stage depends on the outputs of the prepare_train_validation stage as well as on the input data. Let’s take a look at the graph representation to verify this:
! dvc dag
+----------+
| data.dvc |
*+----------+**
** ***
*** **
** ***
+--------------------------+ **
| prepare_train_validation | ***
+--------------------------+ **
** ***
*** ***
** **
+---------------+
| train_network |
+---------------+
Indeed, DVC was able to infer the dependencies between the different stages of our pipeline.
Let’s run the pipeline:
Note
Remember that we are training a neural network here. This step will take a few minutes to run, especially if you are running this using a CPU. For people running on Collab and having selected a GPU, this should be much faster.
! dvc repro
'data.dvc' didn't change, skipping
Stage 'prepare_train_validation' didn't change, skipping
Running stage 'train_network':
> python train.py
************************************************** core>
Fitting model on 300 samples...
Epoch 0: loss = 0.3594, balanced accuracy = 0.5345
Epoch 1: loss = 0.2825, balanced accuracy = 0.7676
Epoch 2: loss = 0.2815, balanced accuracy = 0.6293
Epoch 3: loss = 0.2107, balanced accuracy = 0.8759
Epoch 4: loss = 0.1865, balanced accuracy = 0.7717
Epoch 5: loss = 0.1753, balanced accuracy = 0.9107
Epoch 6: loss = 0.1941, balanced accuracy = 0.9394
Epoch 7: loss = 0.1390, balanced accuracy = 0.8731
Epoch 8: loss = 0.1249, balanced accuracy = 0.8859
Epoch 9: loss = 0.1455, balanced accuracy = 0.7845
Epoch 10: loss = 0.1054, balanced accuracy = 0.9335
Epoch 11: loss = 0.1235, balanced accuracy = 0.9752
Epoch 12: loss = 0.0906, balanced accuracy = 0.9917
Epoch 13: loss = 0.0942, balanced accuracy = 0.9876
Epoch 14: loss = 0.0841, balanced accuracy = 0.9138
Epoch 15: loss = 0.0690, balanced accuracy = 1.0000
Epoch 16: loss = 0.0730, balanced accuracy = 0.9917
Epoch 17: loss = 0.0600, balanced accuracy = 1.0000
Epoch 18: loss = 0.0645, balanced accuracy = 0.9655
Epoch 19: loss = 0.0531, balanced accuracy = 1.0000
Epoch 20: loss = 0.0466, balanced accuracy = 1.0000
Epoch 21: loss = 0.0415, balanced accuracy = 1.0000
Epoch 22: loss = 0.0370, balanced accuracy = 1.0000
Epoch 23: loss = 0.0343, balanced accuracy = 1.0000
Epoch 24: loss = 0.0356, balanced accuracy = 1.0000
Epoch 25: loss = 0.0302, balanced accuracy = 1.0000
Epoch 26: loss = 0.0301, balanced accuracy = 1.0000
Epoch 27: loss = 0.0304, balanced accuracy = 1.0000
Epoch 28: loss = 0.0287, balanced accuracy = 1.0000
Epoch 29: loss = 0.0218, balanced accuracy = 1.0000
**************************************************
Metrics on training set :
{
"accuracy": 1.0,
"sensitivity": 1.0,
"specificity": 1.0,
"balanced_accuracy": 1.0,
"mean_loss": 0.02180203386077968
}
Metrics on validation set :
{
"accuracy": 0.8441558441558441,
"sensitivity": 0.5333333333333333,
"specificity": 0.9193548387096774,
"balanced_accuracy": 0.7263440860215054,
"mean_loss": 0.33561796777996583
}
**************************************************
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
Let’s get some information on the state of our workspace:
! git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: .gitignore
new file: data.dvc
new file: dvc.lock
new file: dvc.yaml
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .gitignore
modified: dvc.lock
modified: dvc.yaml
Untracked files:
(use "git add <file>..." to include in what will be committed)
metrics.json
params.yaml
prepare_train_validation_sets.py
train.py
Let’s version the DVC files as well as our Python scripts and commit the whole thing:
! git add .gitignore dvc.yaml dvc.lock train.py prepare_train_validation_sets.py params.yaml
! git commit -m "First model, trained with images cropped around left HC"
! git tag -a "v1.0" -m "model v1.0, left HC only"
! git log
[main ce277c9] First model, trained with images cropped around left HC
7 files changed, 215 insertions(+)
create mode 100644 .gitignore
create mode 100644 data.dvc
create mode 100644 dvc.lock
create mode 100644 dvc.yaml
create mode 100644 params.yaml
create mode 100644 prepare_train_validation_sets.py
create mode 100644 train.py
commit ce277c9d88d5d5d68c67fd049a791d3aaea40bae (HEAD -> main, tag: v1.0)
Author: John Doe <john.doe@inria.fr>
Date: Mon Nov 20 17:00:28 2023 +0100
First model, trained with images cropped around left HC
commit 9e911d613facecca669e5cdde5daefe5495905d4
Author: John Doe <john.doe@inria.fr>
Date: Mon Nov 20 16:56:27 2023 +0100
initialize DVC
Note that, if we re-run dvc repro, nothing will happen since everything is up-to-date:
! dvc repro
'data.dvc' didn't change, skipping
Stage 'prepare_train_validation' didn't change, skipping
Stage 'train_network' didn't change, skipping
Data and pipelines are up to date.
As a final note on this section, we can take a look at our DVC cache and see that it is much more complicated than the one we had in the previous chapter. Which is expected since we are versioning a much more complex dataset.
! tree .dvc/cache/files/md5 | head -n 15
.dvc/cache/files/md5
├── 00
│ ├── 0f0a17ba2fad49cac27e01dda75227
│ ├── 7b731239f31706f6f178cccc663d6e
│ └── 856eabc382ea856759d3cba228ea34
├── 01
│ ├── 893e13dd8423b1b45529541e2d07f3
│ └── efa41c1fb54398e22ed80984e5ffb0
├── 03
│ └── 2b1a688f5774f4a4dca066479bc5a6
├── 04
│ └── 42bfb85941fe4b4584efb2caaa7448
├── 05
│ ├── 1a3720be4ea7c5f41d5a61e11e50f5
│ ├── 1d51ab05ac9954bcb5bd31d5b525b9
Use both the left and right HC#
Let’s imagine now that we receive additional data in the form of cropped images of the right HC.
Note
Of course we are only pretending here! Recall that we are in fact generating these images from the downloaded raw dataset.
# Generate the cropped images of the right HC
generate_cropped_hc_dataset(
oasis_folder,
hemi="right",
output_folder=Path("./data"),
verbose=False,
)
This changed our input dataset:
! tree data | head -n 16
data
└── subjects
├── sub-OASIS10001
│ └── ses-M00
│ └── deeplearning_prepare_data
│ └── image_based
│ └── custom
│ ├── sub-OASIS10001_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_left.pt
│ └── sub-OASIS10001_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_right.pt
├── sub-OASIS10002
│ └── ses-M00
│ └── deeplearning_prepare_data
│ └── image_based
│ └── custom
│ ├── sub-OASIS10002_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_left.pt
│ └── sub-OASIS10002_ses-M00_T1w_segm-graymatter_space-Ixi549Space_modulated-off_probability_right.pt
As you can see, we now have two images for each subject, one for the left HC that we already had in the previous section, and one for the right HC that we just generated.
We can take a look at these images. For example, plot both HC for a specific subject:
plot_hc(data_folder, 'sub-OASIS10001', "left", cut_coords=(15, 20, 15))
plot_hc(data_folder, 'sub-OASIS10001', "right", cut_coords=(15, 20, 15))
At this point, we want to re-train our model with this larger input dataset.
Given our setup, the only thing we need to do is to update our train and validation dataframes to encode the fact that we now have two samples per subject:
%%writefile -a prepare_train_validation_sets.py
import numpy as np
train_df = train_df.loc[np.repeat(train_df.index, 2)].reset_index(drop=True)
train_df["hemi"][::2] = "right"
valid_df = valid_df.loc[np.repeat(valid_df.index, 2)].reset_index(drop=True)
valid_df["hemi"][::2] = "right"
train_df.to_csv("train.csv")
valid_df.to_csv("validation.csv")
Appending to prepare_train_validation_sets.py
Note
Note that, for simplificity due to the constraints of the notebook format, we just appenned the previous code to the prepare_train_validation_sets.py file instead of modifying it, which would be much cleaner. Feel free to open the python file and replace the relevant portion of the code with the previous cell.
And… that’s all we need to do ! We don’t need to think about what should be re-run and what shouldn’t, DVC is taking care of that for us. We can simply call dvc repro to run the pipeline:
! dvc repro
Verifying data sources in stage: 'data.dvc'
0% Committing data to cache| |416/? [00:00<00:00, 3548.13file/s]
!
0%| |memory://.NMArgWwNsL7GbLobQsBbCb.tm0.00/? [00:00<?, ?B/s]
0%| |memory://.NMArgWwNsL7GbLobQsBbCb0.00/188k [00:00<?, ?B/s]
Running stage 'prepare_train_validation':
> python prepare_train_validation_sets.py
**************************************************
Train dataset:
N age %sexF education MMS CDR=0 CDR=0.5 CDR=1 CDR=2
AD 58 77.4 ± 7.5 69.0 2.8 ± 1.4 22.6 ± 3.6 0 37 19 2
CN 242 43.4 ± 23.5 62.0 3.6 ± 1.2 29.8 ± 0.5 97 0 0 0
**************************************************
Validation dataset:
N age %sexF education MMS CDR=0 CDR=0.5 CDR=1 CDR=2
AD 15 78.2 ± 6.6 40.0 2.5 ± 1.0 22.9 ± 3.6 0 8 7 0
CN 62 46.3 ± 22.6 62.9 3.4 ± 1.3 29.6 ± 0.7 27 0 0 0
**************************************************
Updating lock file 'dvc.lock'
Running stage 'train_network':
> python train.py
************************************************** core>
Fitting model on 600 samples...
Epoch 0: loss = 0.3400, balanced accuracy = 0.5152
Epoch 1: loss = 0.2691, balanced accuracy = 0.6867
Epoch 2: loss = 0.2362, balanced accuracy = 0.7214
Epoch 3: loss = 0.2092, balanced accuracy = 0.7883
Epoch 4: loss = 0.2048, balanced accuracy = 0.7871
Epoch 5: loss = 0.1807, balanced accuracy = 0.8066
Epoch 6: loss = 0.1632, balanced accuracy = 0.8692
Epoch 7: loss = 0.1598, balanced accuracy = 0.8442
Epoch 8: loss = 0.1625, balanced accuracy = 0.9400
Epoch 9: loss = 0.1326, balanced accuracy = 0.9045
Epoch 10: loss = 0.1229, balanced accuracy = 0.9533
Epoch 11: loss = 0.1101, balanced accuracy = 0.9466
Epoch 12: loss = 0.1011, balanced accuracy = 0.9595
Epoch 13: loss = 0.0978, balanced accuracy = 0.9324
Epoch 14: loss = 0.0898, balanced accuracy = 0.9714
Epoch 15: loss = 0.0871, balanced accuracy = 0.9833
Epoch 16: loss = 0.1012, balanced accuracy = 0.9793
Epoch 17: loss = 0.0892, balanced accuracy = 0.9224
Epoch 18: loss = 0.0699, balanced accuracy = 0.9907
Epoch 19: loss = 0.0600, balanced accuracy = 0.9936
Epoch 20: loss = 0.0517, balanced accuracy = 1.0000
Epoch 21: loss = 0.0456, balanced accuracy = 1.0000
Epoch 22: loss = 0.0620, balanced accuracy = 0.9948
Epoch 23: loss = 0.0404, balanced accuracy = 0.9957
Epoch 24: loss = 0.0406, balanced accuracy = 0.9990
Epoch 25: loss = 0.0403, balanced accuracy = 0.9979
Epoch 26: loss = 0.0371, balanced accuracy = 1.0000
Epoch 27: loss = 0.0265, balanced accuracy = 1.0000
Epoch 28: loss = 0.0261, balanced accuracy = 1.0000
Epoch 29: loss = 0.0253, balanced accuracy = 1.0000
**************************************************
Metrics on training set :
{
"accuracy": 1.0,
"sensitivity": 1.0,
"specificity": 1.0,
"balanced_accuracy": 1.0,
"mean_loss": 0.025298228724277578
}
Metrics on validation set :
{
"accuracy": 0.8701298701298701,
"sensitivity": 0.5666666666666667,
"specificity": 0.9435483870967742,
"balanced_accuracy": 0.7551075268817204,
"mean_loss": 0.335043129894063
}
**************************************************
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add data.dvc dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
Let’s take a look at our workspace:
!git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: data.dvc
modified: dvc.lock
modified: prepare_train_validation_sets.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
metrics.json
no changes added to commit (use "git add" and/or "git commit -a")
The Python script was modified by us and DVC modified data.dvc and dvc.lock.
The change to data.dvc is due to the fact that we added more data to our input dataset:
! git diff data.dvc
diff --git a/data.dvc b/data.dvc
index 83a9d15..1ed1629 100644
--- a/data.dvc
+++ b/data.dvc
@@ -1,6 +1,6 @@
outs:
-- md5: 95c25bee3697aa6cae552468a24896ec.dir
- size: 60729344
- nfiles: 416
+- md5: b1ed10dadbabfe38a1d268e0f2699948.dir
+ size: 121460768
+ nfiles: 832
hash: md5
path: data
The changes made to dvc.lock are hash value updates to encode the changes to the dependencies and outputs:
! git diff dvc.lock
diff --git a/dvc.lock b/dvc.lock
index d86683c..f862000 100644
--- a/dvc.lock
+++ b/dvc.lock
@@ -5,42 +5,42 @@ stages:
deps:
- path: data
hash: md5
- md5: 95c25bee3697aa6cae552468a24896ec.dir
- size: 60729344
- nfiles: 416
+ md5: b1ed10dadbabfe38a1d268e0f2699948.dir
+ size: 121460768
+ nfiles: 832
- path: prepare_train_validation_sets.py
hash: md5
- md5: c8015ec57c1b76bd7578e0e8e6a41422
- size: 1139
+ md5: 9bd86d8e38a662457ee8774054239f78
+ size: 1442
outs:
- path: train.csv
hash: md5
- md5: a696d40de31a824be7f8376404da00df
- size: 10432
+ md5: 5abb2353077de518c47ed6f91971b26f
+ size: 21232
- path: validation.csv
hash: md5
- md5: aa08487b3f7ec7c367d9a4c1dba20158
- size: 2650
+ md5: 9f0b08bd7110de35351de613f8db0239
+ size: 5399
train_network:
cmd: python train.py
deps:
- path: data
hash: md5
- md5: 95c25bee3697aa6cae552468a24896ec.dir
- size: 60729344
- nfiles: 416
+ md5: b1ed10dadbabfe38a1d268e0f2699948.dir
+ size: 121460768
+ nfiles: 832
- path: train.csv
hash: md5
- md5: a696d40de31a824be7f8376404da00df
- size: 10432
+ md5: 5abb2353077de518c47ed6f91971b26f
+ size: 21232
- path: train.py
hash: md5
md5: 4b37db644b33a5354a773dc08835f2db
size: 1769
- path: validation.csv
hash: md5
- md5: aa08487b3f7ec7c367d9a4c1dba20158
- size: 2650
+ md5: 9f0b08bd7110de35351de613f8db0239
+ size: 5399
params:
params.yaml:
train.batch_size: 4
@@ -49,13 +49,13 @@ stages:
outs:
- path: metrics.json
hash: md5
- md5: 96000f5353075c77a86f83b27fb2d4c2
- size: 199
+ md5: f6c6b97e310eef152f1c30428f5ed17f
+ size: 197
- path: model.h5
hash: md5
- md5: d38bb2e376e55643586e1d3c0f4cfe35
+ md5: 4ffcbc3604d512ce74a3658abd550c8e
size: 104155
- path: notes.txt
hash: md5
- md5: 24eafe6ea6efb4e1af012d9295c0e151
+ md5: af8001c909b4912cf621aa4de92ca285
size: 123
Let’s commit our changes and tag this as our V2:
! git add data.dvc dvc.lock prepare_train_validation_sets.py
! git commit -m "Second model, trained with images cropped around left and right HC"
! git tag -a "v2.0" -m "model v2.0, left and right HC"
! git log
[main 0fb1160] Second model, trained with images cropped around left and right HC
3 files changed, 33 insertions(+), 23 deletions(-)
commit 0fb116038b5ef5b6bc97e4c10e60d0263afe5b01 (HEAD -> main, tag: v2.0)
Author: John Doe <john.doe@inria.fr>
Date: Mon Nov 20 17:05:36 2023 +0100
Second model, trained with images cropped around left and right HC
commit ce277c9d88d5d5d68c67fd049a791d3aaea40bae (tag: v1.0)
Author: John Doe <john.doe@inria.fr>
Date: Mon Nov 20 17:00:28 2023 +0100
First model, trained with images cropped around left HC
commit 9e911d613facecca669e5cdde5daefe5495905d4
Author: John Doe <john.doe@inria.fr>
Date: Mon Nov 20 16:56:27 2023 +0100
initialize DVC
Reproducing#
As in the previous chapter, imagine that we have to go back to the first version of our experiment. As we saw, we can restore the state of the project with the checkout commands:
! git checkout v1.0
! dvc checkout
Note: switching to 'v1.0'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at ce277c9 First model, trained with images cropped around left HC
Building workspace index |2.92k [00:00, 4.38kentry/s]
Comparing indexes |2.92k [00:02, 1.22kentry/s]
Applying changes |4.00 [00:00, 167file/s]
M validation.csv
M model.h5
M notes.txt
M train.csv
M data/
Now, we are going to see the benefits of having defined our experiment as a data pipeline with DVC.
If we check the status, DVC tells us that there is a change in the run_experiment stage:
! dvc status
train_network:
changed outs:
modified: metrics.json
And, if we run dvc repro, DVC is clever enough to know which stages to run given the dependencies that were modified.
Since we didn’t modify anything besides going back to version 1 of the experiment, DVC won’t re-run anything because everything is already in the cache. It only needs to point to the correct files in the cache:
! dvc repro
'data.dvc' didn't change, skipping
Stage 'prepare_train_validation' didn't change, skipping
Stage 'train_network' is cached - skipping run, checking out outputs
Use `dvc push` to send your updates to remote storage.
We can verify that our human-readable notes correspond to the experiment we are currently running (300 samples with learning rate of 0.0001):
! cat notes.txt
CNN model fitted on 300 samples with hyperparameters:
- learning rate = 0.0001
- number of epochs = 30
- size of batch = 4
Now, let’s imagine we want to experiment the first version of our model with a different learning rate.
All we need to do is to open the params.yaml file and update the parameter to the desired value.
Let’s try increasing it to 10^3:
%%writefile params.yaml
train:
learning_rate: 0.001
n_epochs: 30
batch_size: 4
Overwriting params.yaml
Again, we don’t need to remember what this small change will impact in our experiment. DVC handles this very well:
! dvc repro
'data.dvc' didn't change, skipping
Stage 'prepare_train_validation' didn't change, skipping
Running stage 'train_network':
> python train.py
************************************************** core>
Fitting model on 300 samples...
Epoch 0: loss = 0.2411, balanced accuracy = 0.8470
Epoch 1: loss = 0.3580, balanced accuracy = 0.6531
Epoch 2: loss = 0.3299, balanced accuracy = 0.9050
Epoch 3: loss = 0.1484, balanced accuracy = 0.8697
Epoch 4: loss = 0.1351, balanced accuracy = 0.9166
Epoch 5: loss = 0.3926, balanced accuracy = 0.6552
Epoch 6: loss = 0.3830, balanced accuracy = 0.9132
Epoch 7: loss = 0.1025, balanced accuracy = 0.9031
Epoch 8: loss = 0.0717, balanced accuracy = 0.9700
Epoch 9: loss = 0.0586, balanced accuracy = 0.9548
Epoch 10: loss = 0.0559, balanced accuracy = 0.9790
Epoch 11: loss = 0.0473, balanced accuracy = 0.9807
Epoch 12: loss = 0.0915, balanced accuracy = 0.9711
Epoch 13: loss = 0.0488, balanced accuracy = 0.9897
Epoch 14: loss = 0.0281, balanced accuracy = 0.9979
Epoch 15: loss = 0.1489, balanced accuracy = 0.8103
Epoch 16: loss = 0.1573, balanced accuracy = 0.9463
Epoch 17: loss = 0.2713, balanced accuracy = 0.6810
Epoch 18: loss = 0.0485, balanced accuracy = 0.9569
Epoch 19: loss = 0.0255, balanced accuracy = 0.9959
Epoch 20: loss = 0.1188, balanced accuracy = 0.8534
Epoch 21: loss = 0.0155, balanced accuracy = 1.0000
Epoch 22: loss = 0.0224, balanced accuracy = 0.9959
Epoch 23: loss = 0.0061, balanced accuracy = 1.0000
Epoch 24: loss = 0.0035, balanced accuracy = 1.0000
Epoch 25: loss = 0.0147, balanced accuracy = 0.9979
Epoch 26: loss = 0.0289, balanced accuracy = 0.9938
Epoch 27: loss = 0.0082, balanced accuracy = 1.0000
Epoch 28: loss = 0.0042, balanced accuracy = 1.0000
Epoch 29: loss = 0.0039, balanced accuracy = 1.0000
**************************************************
Metrics on training set :
{
"accuracy": 1.0,
"sensitivity": 1.0,
"specificity": 1.0,
"balanced_accuracy": 1.0,
"mean_loss": 0.003486676831023748
}
Metrics on validation set :
{
"accuracy": 0.8181818181818182,
"sensitivity": 0.6,
"specificity": 0.8709677419354839,
"balanced_accuracy": 0.7354838709677419,
"mean_loss": 0.7196344608341387
}
**************************************************
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
In this case, DVC knows it can re-use the output of the prepare_train_validation stage since none of its dependecies changed. However it has to re-run the train_network stage because there is no results cached which match the new set of dependencies.
We can again look at the notes to see that the learning rate has been changed to the new desired value:
!cat notes.txt
CNN model fitted on 300 samples with hyperparameters:
- learning rate = 0.001
- number of epochs = 30
- size of batch = 4
Cleaning:
# Do not run this unless you want to start over from scratch...
! rm model.*
! rm -rf .git
! rm -rf .dvc
! rm .gitignore
! rm .dvcignore
! rm metrics.json
! rm data.dvc
! rm -r data
! rm train.py prepare_train_validation_sets.py
! rm dvc.*
! rm train.csv validation.csv
! rm notes.txt
! rm params.yaml