
0. Fetching the dataset
Contenu
Note
If running in Colab, think of changing the runtime type before starting, in order to have access to GPU ressources: Runtime->Change Runtime Type, then chose GPU for hardware accelerator.
In this lab we will focus on image synthesis, in particular to synthesize T2-weighted MRI from T1-weighted MRI.
We will investigate three approaches to do so:
First, we will train a generator (or encoder-decoder).
Then, we will train a conditional generative adversarial network (cGAN).
Finally, we will train a cycle generative adversarial network (CycleGAN).
We will evaluate the quality of the generated images using several metrics.
We will use the IXI dataset to have access to paired T1-w and T2-w images. Before creating and training the different neural networks, we will:
fetch the dataset,
have a look at it to see what the task looks like, and
illustrate how to easily access the data.
0. Fetching the dataset¶
The dataset can be found on this
server
and alternatively in the following
GitHub repository.
In the size64 folder, there are 1154 files: 2 images for 577 subjects.
The size of each image is (64, 64).
Let’s download the file and have a look at the data.
# Get the dataset from the server
! git clone https://github.com/Easternwen/IXI-dataset.git
fatal: le chemin de destination 'IXI-dataset' existe déjà et n'est pas un répertoire vide.
The dataset used in this lab is composed of preprocessed images from the IXI dataset. Two different structural MRI modalities are comprised in this dataset:
T1 weighted images
T2 weighted images
These modalities do not highlight the same tissues: for example the CSF voxels are cancelled in T1 weighted imaging whereas they are highlighted by the T2 weighted imaging.
import matplotlib.pyplot as plt
import numpy as np
import os
import torch
root = "./IXI-dataset/size64/"
plt.figure(figsize=(9, 4))
plt.subplot(1, 2, 1)
plt.imshow(np.swapaxes(torch.load(os.path.join(root, 'sub-IXI002 - T1.pt')), 0, 1),
cmap='gray', origin='lower')
plt.title("T1 slice for subject 002")
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(np.swapaxes(torch.load(os.path.join(root, 'sub-IXI002 - T2.pt')), 0, 1),
cmap='gray', origin='lower')
plt.title("T2 slice for subject 002")
plt.axis('off')
plt.show()

Let’s import all the necessary packages.
# torch stuff
import torch
from torch import nn
from torch.utils.data import DataLoader
import torch.nn.functional as F
# torchsummary and torchvision
from torchsummary import summary
from torchvision.utils import save_image
# matplotlib stuff
import matplotlib.pyplot as plt
import matplotlib.image as img
# numpy and pandas
import numpy as np
import pandas as pd
# Common python packages
import datetime
import os
import sys
import time
Let’s create a custom IXIDataset class to easily have access to the data.
Here we don’t use tsv files to split subjects between the training and the
test set. We only set the dataset to the train or test mode to access
training or test data.
class IXIDataset(torch.utils.data.Dataset):
"""Dataset utility class.
Args:
root: (str) Path of the folder with all the images.
mode : {'train' or 'test'} Part of the dataset that is loaded.
"""
def __init__(self, root, mode="train"):
files = sorted(os.listdir(root))
patient_id = list(set([i.split()[0] for i in files]))
imgs = []
if mode == "train":
for i in patient_id[:int(0.8 * len(patient_id))]:
if (
os.path.isfile(os.path.join(root, i + " - T1.pt")) and
os.path.isfile(os.path.join(root, i + " - T2.pt"))
):
imgs.append((os.path.join(root, i + " - T1.pt"),
os.path.join(root, i + " - T2.pt")))
elif mode == "test":
for i in patient_id[int(0.8 * len(patient_id)):]:
if (
os.path.isfile(os.path.join(root, i + " - T1.pt")) and
os.path.isfile(os.path.join(root, i + " - T2.pt"))
):
imgs.append((os.path.join(root, i + " - T1.pt"),
os.path.join(root, i + " - T2.pt")))
self.imgs = imgs
def __getitem__(self, index):
t1_path, t2_path = self.imgs[index]
t1 = torch.load(t1_path)[None, :, :]
t2 = torch.load(t2_path)[None, :, :]
return {"T1": t1, "T2": t2}
def __len__(self):
return len(self.imgs)
Using this class and the DataLoader class from torch.utils.data, you can
easily have access to your dataset. Here is a quick example on how to use it:
# Create a DataLoader instance for the training set
# You will get a batch of samples from the training set
dataloader = DataLoader(
IXIDataset(root, mode="train"),
batch_size=1,
shuffle=False,
)
for batch in dataloader:
# batch is a dictionary with two keys:
# - batch["T1"] is a tensor with shape (batch_size, 64, 64) with the T1 images for the samples in this batch
# - batch["T2"] is a tensor with shape (batch_size, 64, 64) with the T2 images for the samples in this batch
1. Generator¶
1.1 Architecture¶
The generator will have a U-Net architecture with the following characteristics:
the descending blocks are convolutional layers followed by instance normalization with a LeakyReLU activation function;
the ascending blocks are transposed convolutional layers followed by instance normalization with a ReLU activation function.
The parameters for each layer are given in the picture below.
GeneratorUNet class to define the
generator with the architecture given above.
# We provide classes for each block of the U-Net.
class UNetDown(nn.Module):
"""Descending block of the U-Net.
Args:
in_size: (int) number of channels in the input image.
out_size : (int) number of channels in the output image.
"""
def __init__(self, in_size, out_size):
super(UNetDown, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_size, out_size, kernel_size=3, stride=2, padding=1),
nn.InstanceNorm2d(out_size),
nn.LeakyReLU(0.2)
)
def forward(self, x):
return self.model(x)
class UNetUp(nn.Module):
"""Ascending block of the U-Net.
Args:
in_size: (int) number of channels in the input image.
out_size : (int) number of channels in the output image.
"""
def __init__(self, in_size, out_size):
super(UNetUp, self).__init__()
self.model = nn.Sequential(
nn.ConvTranspose2d(in_size, out_size, kernel_size=4,
stride=2, padding=1),
nn.InstanceNorm2d(out_size),
nn.ReLU(inplace=True)
)
def forward(self, x, skip_input=None):
if skip_input is not None:
x = torch.cat((x, skip_input), 1) # add the skip connection
x = self.model(x)
return x
class FinalLayer(nn.Module):
"""Final block of the U-Net.
Args:
in_size: (int) number of channels in the input image.
out_size : (int) number of channels in the output image.
"""
def __init__(self, in_size, out_size):
super(FinalLayer, self).__init__()
self.model = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_size, out_size, kernel_size=3, padding=1),
nn.Tanh(),
)
def forward(self, x, skip_input=None):
if skip_input is not None:
x = torch.cat((x, skip_input), 1) # add the skip connection
x = self.model(x)
return x
class GeneratorUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super(GeneratorUNet, self).__init__()
self.down1 = UNetDown(in_channels, 64)
self.down2 = UNetDown(64, 128)
self.down3 = UNetDown(128, 256)
self.down4 = UNetDown(256, 512)
self.down5 = UNetDown(512, 512)
self.up1 = UNetUp(512, 512)
self.up2 = UNetUp(1024, 256)
self.up3 = UNetUp(512, 128)
self.up4 = UNetUp(256, 64)
self.final = FinalLayer(128, 1)
def forward(self, x):
d1 = self.down1(x)
d2 = self.down2(d1)
d3 = self.down3(d2)
d4 = self.down4(d3)
d5 = self.down5(d4)
u1 = self.up1(d5)
u2 = self.up2(u1, d4)
u3 = self.up3(u2, d3)
u4 = self.up4(u3, d2)
return self.final(u4, d1)
Let’s have a look at the architecture of our generator:
# Summary of the generator
summary(GeneratorUNet().cuda(), (1, 64, 64) )
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 640
InstanceNorm2d-2 [-1, 64, 32, 32] 0
LeakyReLU-3 [-1, 64, 32, 32] 0
UNetDown-4 [-1, 64, 32, 32] 0
Conv2d-5 [-1, 128, 16, 16] 73,856
InstanceNorm2d-6 [-1, 128, 16, 16] 0
LeakyReLU-7 [-1, 128, 16, 16] 0
UNetDown-8 [-1, 128, 16, 16] 0
Conv2d-9 [-1, 256, 8, 8] 295,168
InstanceNorm2d-10 [-1, 256, 8, 8] 0
LeakyReLU-11 [-1, 256, 8, 8] 0
UNetDown-12 [-1, 256, 8, 8] 0
Conv2d-13 [-1, 512, 4, 4] 1,180,160
InstanceNorm2d-14 [-1, 512, 4, 4] 0
LeakyReLU-15 [-1, 512, 4, 4] 0
UNetDown-16 [-1, 512, 4, 4] 0
Conv2d-17 [-1, 512, 2, 2] 2,359,808
InstanceNorm2d-18 [-1, 512, 2, 2] 0
LeakyReLU-19 [-1, 512, 2, 2] 0
UNetDown-20 [-1, 512, 2, 2] 0
ConvTranspose2d-21 [-1, 512, 4, 4] 4,194,816
InstanceNorm2d-22 [-1, 512, 4, 4] 0
ReLU-23 [-1, 512, 4, 4] 0
UNetUp-24 [-1, 512, 4, 4] 0
ConvTranspose2d-25 [-1, 256, 8, 8] 4,194,560
InstanceNorm2d-26 [-1, 256, 8, 8] 0
ReLU-27 [-1, 256, 8, 8] 0
UNetUp-28 [-1, 256, 8, 8] 0
ConvTranspose2d-29 [-1, 128, 16, 16] 1,048,704
InstanceNorm2d-30 [-1, 128, 16, 16] 0
ReLU-31 [-1, 128, 16, 16] 0
UNetUp-32 [-1, 128, 16, 16] 0
ConvTranspose2d-33 [-1, 64, 32, 32] 262,208
InstanceNorm2d-34 [-1, 64, 32, 32] 0
ReLU-35 [-1, 64, 32, 32] 0
UNetUp-36 [-1, 64, 32, 32] 0
Upsample-37 [-1, 128, 64, 64] 0
Conv2d-38 [-1, 1, 64, 64] 1,153
Tanh-39 [-1, 1, 64, 64] 0
FinalLayer-40 [-1, 1, 64, 64] 0
================================================================
Total params: 13,611,073
Trainable params: 13,611,073
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 11.66
Params size (MB): 51.92
Estimated Total Size (MB): 63.59
----------------------------------------------------------------
1.2 Train the generator¶
In order to train the generator, we will repeat the following process:
Generate T2-w images from T1-w images.
Compute the error between the true T2-w images and the generated T2-w images.
Update the parameters of the generators.
The training phase looks like this:
# For each epoch
# For each batch
# Generate fake images for all the images in this batch
# Compute the loss for the generator
# Perform one optimization step
def train_generator(train_loader, test_loader, num_epoch=500,
lr=0.0001, beta1=0.9, beta2=0.999):
"""Train a generator on its own.
Args:
train_loader: (DataLoader) a DataLoader wrapping the training dataset
test_loader: (DataLoader) a DataLoader wrapping the test dataset
num_epoch: (int) number of epochs performed during training
lr: (float) learning rate of the discriminator and generator Adam optimizers
beta1: (float) beta1 coefficient of the discriminator and generator Adam optimizers
beta2: (float) beta1 coefficient of the discriminator and generator Adam optimizers
Returns:
generator: (nn.Module) the trained generator
"""
cuda = True if torch.cuda.is_available() else False
print(f"Using cuda device: {cuda}") # check if GPU is used
# Tensor type (put everything on GPU if possible)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# Output folder
if not os.path.exists("./images/generator"):
os.makedirs("./images/generator")
# Loss function
criterion = torch.nn.L1Loss() # A loss for a voxel-wise comparison of images like torch.nn.L1Loss
# Initialize the generator
generator = GeneratorUNet()
if cuda:
generator = generator.cuda()
criterion.cuda()
# Optimizer
optimizer = torch.optim.Adam(generator.parameters(),
lr=lr, betas=(beta1, beta2))
def sample_images(epoch):
"""Saves a generated sample from the validation set"""
imgs = next(iter(test_loader))
real_A = imgs["T1"].type(Tensor)
real_B = imgs["T2"].type(Tensor)
fake_B = generator(real_A)
img_sample = torch.cat((real_A.data, fake_B.data, real_B.data), -2)
save_image(img_sample, f"./images/generator/epoch-{epoch}.png",
nrow=5, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(num_epoch):
for i, batch in enumerate(train_loader):
# Inputs T1-w and T2-w
real_t1 = batch["T1"].type(Tensor)
real_t2 = batch["T2"].type(Tensor)
# Remove stored gradients
optimizer.zero_grad()
# Generate fake T2 images from the true T1 images
fake_t2 = generator(real_t1)
# Compute the corresponding loss
loss = criterion(fake_t2, real_t2)
# Compute the gradient and perform one optimization step
loss.backward()
optimizer.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(train_loader) + i
batches_left = num_epoch * len(train_loader) - batches_done
time_left = datetime.timedelta(
seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [Loss: %f] ETA: %s"
% (
epoch + 1,
num_epoch,
i,
len(train_loader),
loss.item(),
time_left,
)
)
# Save images at the end of each epoch
sample_images(epoch)
return generator
# Parameters for Adam optimizer
lr = 0.0002
beta1 = 0.5
beta2 = 0.999
# Create dataloaders
batch_size = 40
train_loader = DataLoader(IXIDataset(root, mode="train"),
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(IXIDataset(root, mode="test"),
batch_size=5,
shuffle=False)
# Number of epochs
num_epoch = 20
# Train the generator
generator = train_generator(train_loader, test_loader, num_epoch=num_epoch,
lr=lr, beta1=beta1, beta2=beta2)
1.3 Evaluate the generator¶
Let’s visualize a few generated T2-weighted images:
im = img.imread(f'./images/generator/epoch-{num_epoch - 1}.png')
plt.figure(figsize=(20, 20))
plt.imshow(np.swapaxes(im, 0, 1))
plt.gca().invert_yaxis()
plt.show()
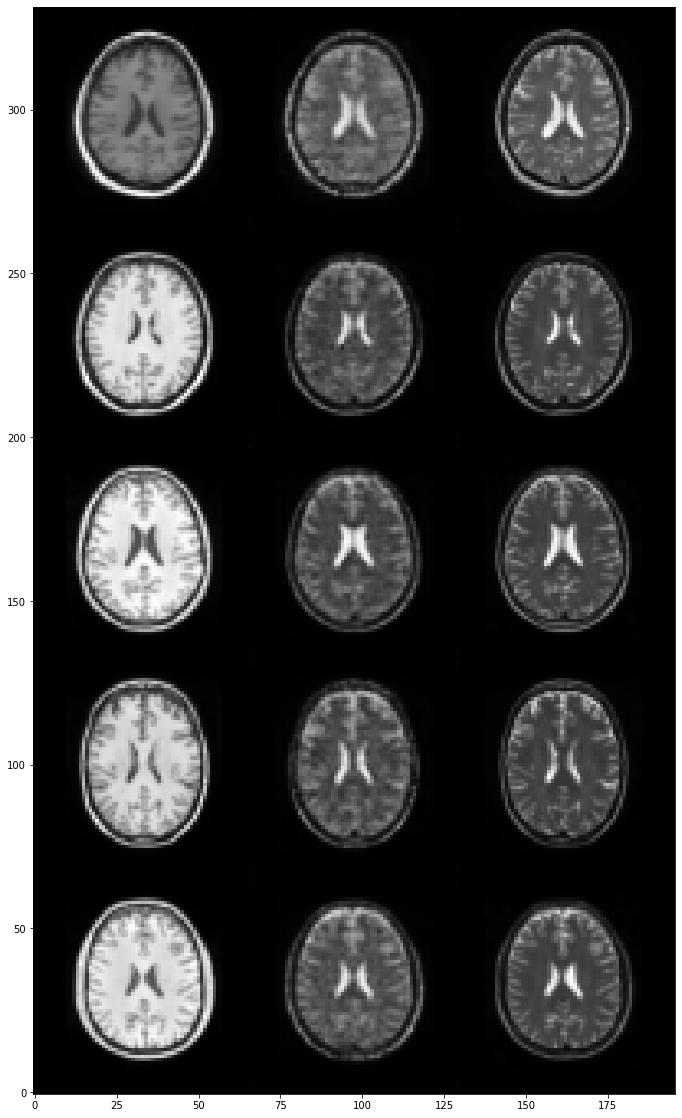
After doing visual quality control, it is a good idea to quantify the quality of the generated images using specific metrics. Some popular metrics include the Mean Absolute Error (MAE), the Peak Signal-to-Noise Ratio (PSNR) and the Structural Similarity index (SSIM):
MAE = \(\displaystyle \frac{1}{nm} \sum_{i=1}^n \sum_{j=1}^m \vert T_{ij} - G_{ij} \vert \)
PSNR = \(\displaystyle -10 \log_{10} \left( \frac{1}{nm} \sum_{i=1}^n \sum_{j=1}^m (T_{ij} - G_{ij})^2 \right) \)
SSIM = \(\displaystyle \frac{(2 \mu_T \mu_G + C_1)(2 \sigma_{TG} + C_2)}{(\mu_T^2 + \mu_G^2 + C_1)(\sigma_T^2 + \sigma_G^2 + C_2)} \) where:
\(\mu\) and \(\sigma\) are the mean value and standard deviation of an image respectively, and
\(C_1\) and \(C_2\) are two positive constants (one can take \(C_1=0.01\) and \(C_2=0.03\)).
The mean absolute error is simply the mean of each absolute value of the difference between the true pixel (\(T_{ij}\)) and the generated pixel (\(G_{ij}\)). The lower, the better. Minimum value is 0.
The peak signal-to-noise ratio is a function of the mean squared error and allows for comparing images encoded with different scales. We simplified its formula in our case. The higher, the better. Maximum value is \(+\infty\).
The structural similarity index is a weighted combination of the luminance, the contrast and the structure. The higher, the better. Maximum value is 1.
For those interested, you can find here a reference to better understand the differences between these metrics.
We provide an implementation for each metric with the functions below.
def mean_absolute_error(image_true, image_generated):
"""Compute mean absolute error.
Args:
image_true: (Tensor) true image
image_generated: (Tensor) generated image
Returns:
mse: (float) mean squared error
"""
return torch.abs(image_true - image_generated).mean()
def peak_signal_to_noise_ratio(image_true, image_generated):
""""Compute peak signal-to-noise ratio.
Args:
image_true: (Tensor) true image
image_generated: (Tensor) generated image
Returns:
psnr: (float) peak signal-to-noise ratio"""
mse = ((image_true - image_generated) ** 2).mean().cpu()
return -10 * np.log10(mse)
def structural_similarity_index(image_true, image_generated, C1=0.01, C2=0.03):
"""Compute structural similarity index.
Args:
image_true: (Tensor) true image
image_generated: (Tensor) generated image
C1: (float) variable to stabilize the denominator
C2: (float) variable to stabilize the denominator
Returns:
ssim: (float) mean squared error"""
mean_true = image_true.mean()
mean_generated = image_generated.mean()
std_true = image_true.std()
std_generated = image_generated.std()
covariance = (
(image_true - mean_true) * (image_generated - mean_generated)).mean()
numerator = (2 * mean_true * mean_generated + C1) * (2 * covariance + C2)
denominator = ((mean_true ** 2 + mean_generated ** 2 + C1) *
(std_true ** 2 + std_generated ** 2 + C2))
return numerator / denominator
We will now evaluate the generator with these three metrics on both the training set and the test set by computing the mean value for each metric.
def evaluate_generator(generator):
"""Evaluate a generator.
Args:
generator: (GeneratorUNet) neural network generating T2-w images
"""
res_train, res_test = [], []
cuda = True if torch.cuda.is_available() else False
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
with torch.no_grad():
for i, batch in enumerate(train_loader):
# Inputs T1-w and T2-w
real_t1 = batch["T1"].type(Tensor)
real_t2 = batch["T2"].type(Tensor)
fake_t2 = generator(real_t1)
mae = mean_absolute_error(real_t2, fake_t2).item()
psnr = peak_signal_to_noise_ratio(real_t2, fake_t2).item()
ssim = structural_similarity_index(real_t2, fake_t2).item()
res_train.append([mae, psnr, ssim])
for i, batch in enumerate(test_loader):
# Inputs T1-w and T2-w
real_t1 = batch["T1"].type(Tensor)
real_t2 = batch["T2"].type(Tensor)
fake_t2 = generator(real_t1)
mae = mean_absolute_error(real_t2, fake_t2).item()
psnr = peak_signal_to_noise_ratio(real_t2, fake_t2).item()
ssim = structural_similarity_index(real_t2, fake_t2).item()
res_test.append([mae, psnr, ssim])
df = pd.DataFrame([
pd.DataFrame(res_train, columns=['MAE', 'PSNR', 'SSIM']).mean().squeeze(),
pd.DataFrame(res_test, columns=['MAE', 'PSNR', 'SSIM']).mean().squeeze()
], index=['Training set', 'Test set']).T
return df
evaluate_generator(generator)
| Training set | Test set | |
|---|---|---|
| MAE | 0.039783 | 0.049175 |
| PSNR | 22.073784 | 20.190939 |
| SSIM | 0.980117 | 0.967832 |
The performance is already really good! The task may be pretty easy. Let’s see if we can still improve the performance with a more complex neural network.
2. Conditional Generative Adversarial Network (cGAN)¶
A generative adversarial network (GAN) is a network generating new samples. A typical GAN consists of two networks:
a generator that generates new samples, and
a discriminator that discriminate generated samples from true samples.
One can think of the generator as a counterfeiter and the discriminator as a authenticator. The discriminator aims at improving the generator by having an opposition. The discriminator must not be too good, otherwise the generator won’t improve. The generator and the discriminator are trained simultaneously and help each other improve.
A conditional generative adversarial network (cGAN) is a particular case of a GAN that is conditioned by the true sample. A conditional GAN can thus only be used when paired samples are available.
2.1 Architecture of the cGAN¶
Like a GAN, a cGAN has two networks:
a generator that generates new samples, and
a discriminator that discriminate generated samples from true samples.
We will keep the same architecture for the generator.
For the discriminator we will use a two-dimensional convolutional neural network with 5 layers:
the first 4 layers are 2D-convolutional layers with a LeakyReLU activation function;
the last layer is a 2D-convolutional layer.
The parameters for each layer are given in the figure below. Don’t forget that the input of the discriminator will be the generated image and the true image since we are using a conditional GAN. Therefore, the number of input channels for the first layer will be two (one for each image).
Discriminator class to define the
discriminator with the architecture given above.
# We provide a function to generate a block for the given architecture.
def discriminator_block(in_filters, out_filters):
"""Return downsampling layers of each discriminator block"""
layers = [nn.Conv2d(in_filters, out_filters, 3, stride=2, padding=1)]
layers.append(nn.LeakyReLU(0.2, inplace=True))
return nn.Sequential(*layers)
class Discriminator(nn.Module):
def __init__(self, in_channels=1):
super(Discriminator, self).__init__()
self.layers = nn.Sequential(
discriminator_block(in_channels*2, 64),
discriminator_block(64, 128),
discriminator_block(128, 256),
discriminator_block(256, 512),
nn.Conv2d(512, 1, 1, stride=4, padding=0),
)
def forward(self, img_A, img_B):
# Concatenate image and condition image by channels to produce input
img_input = torch.cat((img_A, img_B), 1)
return self.layers(img_input)
Let’s have a look at the architecture of our discriminator:
# Summary of the discriminator
summary(Discriminator().cuda(), [(1, 64, 64), (1, 64, 64)])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 1,216
LeakyReLU-2 [-1, 64, 32, 32] 0
Conv2d-3 [-1, 128, 16, 16] 73,856
LeakyReLU-4 [-1, 128, 16, 16] 0
Conv2d-5 [-1, 256, 8, 8] 295,168
LeakyReLU-6 [-1, 256, 8, 8] 0
Conv2d-7 [-1, 512, 4, 4] 1,180,160
LeakyReLU-8 [-1, 512, 4, 4] 0
Conv2d-9 [-1, 1, 1, 1] 513
================================================================
Total params: 1,550,913
Trainable params: 1,550,913
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 64.00
Forward/backward pass size (MB): 1.88
Params size (MB): 5.92
Estimated Total Size (MB): 71.79
----------------------------------------------------------------
2.2 Training our conditional GAN¶
Now that we have created our generator and our discriminator, we have to train them on the dataset.
Notations
\(X_{T1}\): true T1 image;
\(X_{T2}\): true T2 image;
\(\tilde{X}_{T2}\): generated T2 image from \(X_{T1}\);
\(\hat{y}_{X}\): probability returned by the discriminator that the \({X}_{T2}\) is real;
\(\hat{y}_{\tilde{X}}\): probability returned by the discriminator that the \(\tilde{X}_{T2}\) is real.
Training the generator
The loss for the generator is the sum of:
the binary cross-entropy loss between the predicted probabilities of the generated images and positive labels,
the pixel-wise mean absolute error between the generated image and the true image.
For one sample, it is then:
Training the discriminator
The loss for the generator is the mean of:
the binary cross-entropy loss between the predicted probabilities of the generated images and negative labels,
the binary cross-entropy loss between the predicted probabilities of the true images and positive labels.
For one sample, it is then:
Training phase
The generator and the discriminator are trained simultaneously, which makes the training phase look like this:
# For each epoch
# For each batch
# Generate fake images for all the images in this batch
# Compute the loss for the generator and perform one optimization step
# Compute the loss for the discriminator and perform one optimization step
def train_cgan(train_loader, test_loader, num_epoch=500,
lr=0.0001, beta1=0.9, beta2=0.999):
"""Train a conditional GAN.
Args:
train_loader: (DataLoader) a DataLoader wrapping a the training dataset
test_loader: (DataLoader) a DataLoader wrapping a the test dataset
num_epoch: (int) number of epochs performed during training
lr: (float) learning rate of the discriminator and generator Adam optimizers
beta1: (float) beta1 coefficient of the discriminator and generator Adam optimizers
beta2: (float) beta1 coefficient of the discriminator and generator Adam optimizers
Returns:
generator: (nn.Module) the trained generator
"""
cuda = True if torch.cuda.is_available() else False
print(f"Using cuda device: {cuda}") # check if GPU is used
# Tensor type (put everything on GPU if possible)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# Output folder
if not os.path.exists("./images/cgan"):
os.makedirs("./images/cgan")
# Loss functions
criterion_GAN = torch.nn.BCEWithLogitsLoss() # A loss adapted to binary classification like torch.nn.BCEWithLogitsLoss
criterion_pixelwise = torch.nn.L1Loss() # A loss for a voxel-wise comparison of images like torch.nn.L1Loss
lambda_GAN = 1. # Weights criterion_GAN in the generator loss
lambda_pixel = 1. # Weights criterion_pixelwise in the generator loss
# Initialize generator and discriminator
generator = GeneratorUNet()
discriminator = Discriminator()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion_GAN.cuda()
criterion_pixelwise.cuda()
# Optimizers
optimizer_generator = torch.optim.Adam(
generator.parameters(), lr=lr, betas=(beta1, beta2))
optimizer_discriminator = torch.optim.Adam(
discriminator.parameters(), lr=lr, betas=(beta1, beta2))
def sample_images(epoch):
"""Saves a generated sample from the validation set"""
imgs = next(iter(test_loader))
real_t1 = imgs["T1"].type(Tensor)
real_t2 = imgs["T2"].type(Tensor)
fake_t2 = generator(real_t1)
img_sample = torch.cat((real_t1.data, fake_t2.data, real_t2.data), -2)
save_image(img_sample, f"./images/cgan/epoch-{epoch}.png",
nrow=5, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(num_epoch):
for i, batch in enumerate(train_loader):
# Inputs T1-w and T2-w
real_t1 = batch["T1"].type(Tensor)
real_t2 = batch["T2"].type(Tensor)
# Create labels
valid = Tensor(np.ones((real_t2.size(0), 1, 1, 1)))
fake = Tensor(np.zeros((real_t2.size(0), 1, 1, 1)))
# -----------------
# Train Generator
# -----------------
optimizer_generator.zero_grad()
# GAN loss
fake_t2 = generator(real_t1)
pred_fake = discriminator(fake_t2, real_t1)
loss_GAN = criterion_GAN(pred_fake, valid)
# L1 loss
loss_pixel = criterion_pixelwise(fake_t2, real_t2)
# Total loss
loss_generator = lambda_GAN * loss_GAN + lambda_pixel * loss_pixel
# Compute the gradient and perform one optimization step
loss_generator.backward()
optimizer_generator.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_discriminator.zero_grad()
# Real loss
pred_real = discriminator(real_t2, real_t1)
loss_real = criterion_GAN(pred_real, valid)
# Fake loss
fake_t2 = generator(real_t1)
pred_fake = discriminator(fake_t2.detach(), real_t1)
loss_fake = criterion_GAN(pred_fake, fake)
# Total loss
loss_discriminator = 0.5 * (loss_real + loss_fake)
# Compute the gradient and perform one optimization step
loss_discriminator.backward()
optimizer_discriminator.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(train_loader) + i
batches_left = num_epoch * len(train_loader) - batches_done
time_left = datetime.timedelta(
seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] "
"[G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (
epoch + 1,
num_epoch,
i,
len(train_loader),
loss_discriminator.item(),
loss_generator.item(),
loss_pixel.item(),
loss_GAN.item(),
time_left,
)
)
# Save images at the end of each epoch
sample_images(epoch)
return generator
generator_cgan = train_cgan(train_loader, test_loader, num_epoch=num_epoch,
lr=lr, beta1=beta1, beta2=beta2)
2.3 Evaluating the generator of our cGAN¶
Let’s visualize a few generated T2-weighted images:
plt.figure(figsize=(20, 20))
im = img.imread(f'./images/cgan/epoch-{num_epoch - 1}.png')
plt.imshow(np.swapaxes(im, 0, 1))
plt.gca().invert_yaxis()
plt.show()
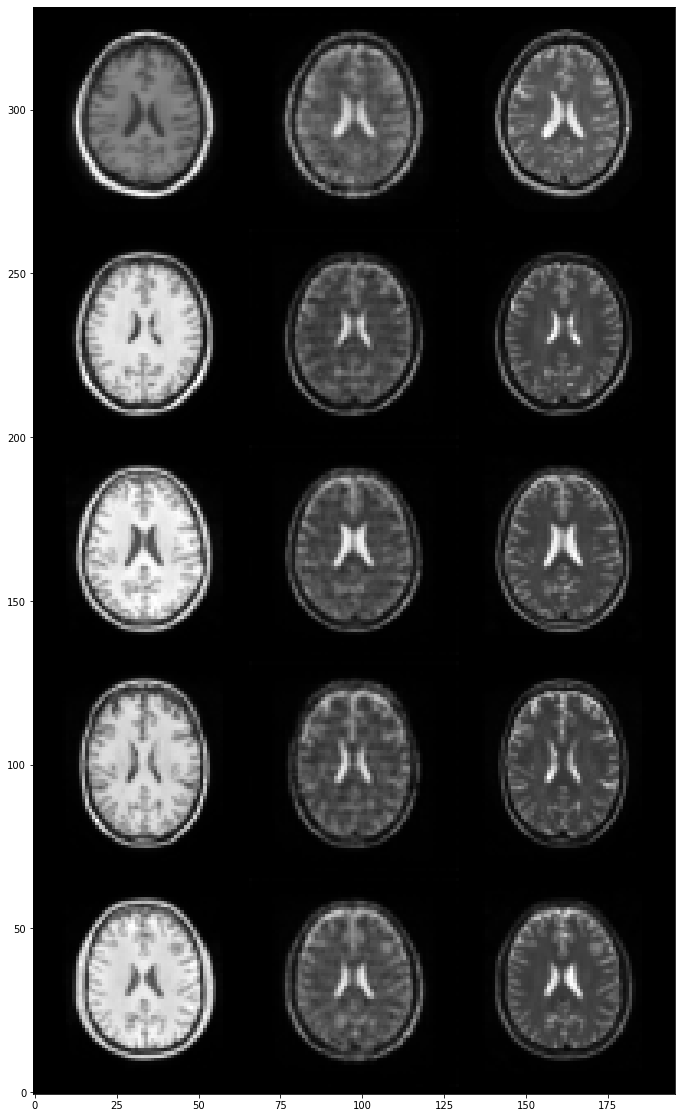
We will now evaluate the generator of the cGAN with the same three metrics on both the training set and the test set by computing the mean value for each metric:
evaluate_generator(generator_cgan)
| Training set | Test set | |
|---|---|---|
| MAE | 0.036712 | 0.046239 |
| PSNR | 22.564912 | 20.575516 |
| SSIM | 0.981744 | 0.969868 |
The performance is slightly lower for the cGAN, which is a bit disappointing. This may be explained by the ease of the task and increase the complexity of the architecture does not help. Another possibility would be to increase the number of epochs, which we did not change in comparison to the architecture with the generator alone.
Let’s now try a more general approach that does not require paired samples.
3. CycleGAN¶
A cycle generative adversarial network (CycleGAN) is a technique for training unsupervised image translation models via the GAN architecture using unpaired collections of images from two different domains. The main innovation of a CycleGAN is to introduce a cycle consistency loss to enforce good reconstruction in both domains.
A CycleGAN consists of two GAN:
one generating samples from domain A to domain B, and
another one generating from domain B to domain A.
The cycle consistency consists in generating from one domain to the other domain then generating back from the second domain to the first domain, and comparing the generated sample from the original sample. The image below (taken from the original paper introducing CycleGAN) summarizes the main concepts of a CycleGAN:

3.1 Architecture of the CycleGAN¶
The discriminators of the CycleGAN do not have the true sample as input.
Thus, we have to remove the true sample in the forward method.
Otherwise, we will use the same architectures for the generators and for the discriminators as the ones from the conditional GAN.
class DiscriminatorCycle(nn.Module):
def __init__(self, in_channels=1):
super(DiscriminatorCycle, self).__init__()
layers = []
layers.extend(discriminator_block(in_channels, 64))
layers.extend(discriminator_block(64, 128))
layers.extend(discriminator_block(128, 256))
layers.extend(discriminator_block(256, 512))
layers.append(nn.Conv2d(512, 1, 4, padding=0))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
Let’s have a look at the architecture of one discriminator in our CycleGAN:
# Summary of one discriminator in the CycleGAN
summary(DiscriminatorCycle().cuda(), [(1, 64, 64)])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 640
LeakyReLU-2 [-1, 64, 32, 32] 0
Conv2d-3 [-1, 128, 16, 16] 73,856
LeakyReLU-4 [-1, 128, 16, 16] 0
Conv2d-5 [-1, 256, 8, 8] 295,168
LeakyReLU-6 [-1, 256, 8, 8] 0
Conv2d-7 [-1, 512, 4, 4] 1,180,160
LeakyReLU-8 [-1, 512, 4, 4] 0
Conv2d-9 [-1, 1, 1, 1] 8,193
================================================================
Total params: 1,558,017
Trainable params: 1,558,017
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 1.88
Params size (MB): 5.94
Estimated Total Size (MB): 7.83
----------------------------------------------------------------
3.2 Training the CycleGAN¶
The generators and the discriminators are trained simultaneously, which makes the training phase look like this:
# For each epoch
# For each batch
# T1 -> T2 -> T1 cycle
## Generate fake T2-weighted images for all the T1-weighted images in this batch
## Generate fake T1-weighted images for all the fake generated T2-weighted images in this batch
## Compute the loss for both generators and perform one optimization step
## Compute the loss for both discriminators and perform one optimization step
# T2 -> T1 -> T2 cycle
## Generate fake T1-weighted images for all the T2-weighted images in this batch
## Generate fake T2-weighted images for all the fake generated T1-weighted images in this batch
## Compute the loss for both generators and perform one optimization step
## Compute the loss for both discriminators and perform one optimization step
def train_cyclegan(train_loader, test_loader, num_epoch=500,
lr=0.0001, beta1=0.9, beta2=0.999):
"""Train a CycleGAN.
Args:
train_loader: (DataLoader) a DataLoader wrapping a the training dataset
test_loader: (DataLoader) a DataLoader wrapping a the test dataset
num_epoch: (int) number of epochs performed during training
lr: (float) learning rate of the discriminator and generator Adam optimizers
beta1: (float) beta1 coefficient of the discriminator and generator Adam optimizers
beta2: (float) beta1 coefficient of the discriminator and generator Adam optimizers
Returns:
generator: (nn.Module) the generator generating T2-w images from T1-w images.
"""
cuda = True if torch.cuda.is_available() else False
print(f"Using cuda device: {cuda}") # check if GPU is used
# Tensor type (put everything on GPU if possible)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# Output folder
if not os.path.exists("./images/cyclegan"):
os.makedirs("./images/cyclegan")
# Loss functions
criterion_GAN_from_t1_to_t2 = torch.nn.BCEWithLogitsLoss() # A loss adapted to binary classification like torch.nn.BCEWithLogitsLoss
criterion_GAN_from_t2_to_t1 = torch.nn.BCEWithLogitsLoss() # A loss adapted to binary classification like torch.nn.BCEWithLogitsLoss
criterion_pixelwise_from_t1_to_t2 = torch.nn.L1Loss() # A loss for a voxel-wise comparison of images like torch.nn.L1Loss
criterion_pixelwise_from_t2_to_t1 = torch.nn.L1Loss() # A loss for a voxel-wise comparison of images like torch.nn.L1Loss
lambda_GAN = 1. # Weights criterion_GAN in the generator loss
lambda_pixel = 1. # Weights criterion_pixelwise in the generator loss
# Initialize generators and discriminators
generator_from_t1_to_t2 = GeneratorUNet()
generator_from_t2_to_t1 = GeneratorUNet()
discriminator_from_t1_to_t2 = DiscriminatorCycle()
discriminator_from_t2_to_t1 = DiscriminatorCycle()
if cuda:
generator_from_t1_to_t2 = generator_from_t1_to_t2.cuda()
generator_from_t2_to_t1 = generator_from_t2_to_t1.cuda()
discriminator_from_t1_to_t2 = discriminator_from_t1_to_t2.cuda()
discriminator_from_t2_to_t1 = discriminator_from_t2_to_t1.cuda()
criterion_GAN_from_t1_to_t2 = criterion_GAN_from_t1_to_t2.cuda()
criterion_GAN_from_t2_to_t1 = criterion_GAN_from_t2_to_t1.cuda()
criterion_pixelwise_from_t1_to_t2 = criterion_pixelwise_from_t1_to_t2.cuda()
criterion_pixelwise_from_t2_to_t1 = criterion_pixelwise_from_t2_to_t1.cuda()
# Optimizers
optimizer_generator_from_t1_to_t2 = torch.optim.Adam(
generator_from_t1_to_t2.parameters(), lr=lr, betas=(beta1, beta2))
optimizer_generator_from_t2_to_t1 = torch.optim.Adam(
generator_from_t2_to_t1.parameters(), lr=lr, betas=(beta1, beta2))
optimizer_discriminator_from_t1_to_t2 = torch.optim.Adam(
discriminator_from_t1_to_t2.parameters(), lr=lr, betas=(beta1, beta2))
optimizer_discriminator_from_t2_to_t1 = torch.optim.Adam(
discriminator_from_t2_to_t1.parameters(), lr=lr, betas=(beta1, beta2))
def sample_images(epoch):
"""Saves a generated sample from the validation set"""
imgs = next(iter(test_loader))
real_t1 = imgs["T1"].type(Tensor)
real_t2 = imgs["T2"].type(Tensor)
fake_t2 = generator_from_t1_to_t2(real_t1)
img_sample = torch.cat((real_t1.data, fake_t2.data, real_t2.data), -2)
save_image(img_sample, f"./images/cyclegan/epoch-{epoch}.png",
nrow=5, normalize=True)
# ----------
# Training
# ----------
prev_time = time.time()
for epoch in range(num_epoch):
for i, batch in enumerate(train_loader):
# Inputs T1-w and T2-w
real_t1 = batch["T1"].type(Tensor)
real_t2 = batch["T2"].type(Tensor)
# Create labels
valid_t1 = Tensor(np.ones((real_t1.size(0), 1, 1, 1)))
imitation_t1 = Tensor(np.zeros((real_t1.size(0), 1, 1, 1)))
valid_t2 = Tensor(np.ones((real_t2.size(0), 1, 1, 1)))
imitation_t2 = Tensor(np.zeros((real_t2.size(0), 1, 1, 1)))
# ------------------
# Train Generators
# ------------------
optimizer_generator_from_t1_to_t2.zero_grad()
optimizer_generator_from_t2_to_t1.zero_grad()
# GAN loss
fake_t2 = generator_from_t1_to_t2(real_t1)
pred_fake_t2 = discriminator_from_t1_to_t2(fake_t2)
loss_GAN_from_t1_to_t2 = criterion_GAN_from_t1_to_t2(pred_fake_t2, valid_t2)
fake_t1 = generator_from_t2_to_t1(real_t2)
pred_fake_t1 = discriminator_from_t2_to_t1(fake_t1)
loss_GAN_from_t2_to_t1 = criterion_GAN_from_t2_to_t1(pred_fake_t1, valid_t1)
# L1 loss
fake_fake_t1 = generator_from_t2_to_t1(fake_t2)
loss_pixel_from_t1_to_t2 = criterion_pixelwise_from_t1_to_t2(fake_fake_t1, real_t1)
fake_fake_t2 = generator_from_t1_to_t2(fake_t1)
loss_pixel_from_t2_to_t1 = criterion_pixelwise_from_t2_to_t1(fake_fake_t2, real_t2)
# Total loss
loss_generator_from_t1_to_t2 = (lambda_GAN * loss_GAN_from_t1_to_t2 +
lambda_pixel * loss_pixel_from_t1_to_t2)
loss_generator_from_t2_to_t1 = (lambda_GAN * loss_GAN_from_t2_to_t1 +
lambda_pixel * loss_pixel_from_t2_to_t1)
loss_generator_from_t1_to_t2.backward()
loss_generator_from_t2_to_t1.backward()
optimizer_generator_from_t1_to_t2.step()
optimizer_generator_from_t2_to_t1.step()
# ----------------------
# Train Discriminators
# ----------------------
optimizer_discriminator_from_t1_to_t2.zero_grad()
optimizer_discriminator_from_t2_to_t1.zero_grad()
# Real loss
pred_real_t2 = discriminator_from_t1_to_t2(real_t2)
loss_real_t2 = criterion_GAN_from_t1_to_t2(pred_real_t2, valid_t2)
pred_real_t1 = discriminator_from_t2_to_t1(real_t1)
loss_real_t1 = criterion_GAN_from_t2_to_t1(pred_real_t1, valid_t1)
# Fake loss
fake_t2 = generator_from_t1_to_t2(real_t1)
pred_fake_t2 = discriminator_from_t1_to_t2(fake_t2.detach())
loss_fake_t2 = criterion_GAN_from_t1_to_t2(pred_fake_t2, imitation_t2)
fake_t1 = generator_from_t2_to_t1(real_t2)
pred_fake_t1 = discriminator_from_t2_to_t1(fake_t1.detach())
loss_fake_t1 = criterion_GAN_from_t2_to_t1(pred_fake_t1, imitation_t1)
# Total loss
loss_discriminator_from_t1_to_t2 = 0.5 * (loss_real_t2 + loss_fake_t2)
loss_discriminator_from_t2_to_t1 = 0.5 * (loss_real_t1 + loss_fake_t1)
loss_discriminator_from_t1_to_t2.backward()
loss_discriminator_from_t2_to_t1.backward()
optimizer_discriminator_from_t1_to_t2.step()
optimizer_discriminator_from_t2_to_t1.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(train_loader) + i
batches_left = num_epoch * len(train_loader) - batches_done
time_left = datetime.timedelta(
seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()
# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] "
"[Generator losses: %f, %f] "
"[Discriminator losses: %f, %f] "
"ETA: %s"
% (
epoch + 1,
num_epoch,
i,
len(train_loader),
loss_generator_from_t1_to_t2.item(),
loss_generator_from_t2_to_t1.item(),
loss_discriminator_from_t1_to_t2.item(),
loss_discriminator_from_t2_to_t1.item(),
time_left,
)
)
# Save images at the end of each epoch
sample_images(epoch)
return generator_from_t1_to_t2
generator_cyclegan = train_cyclegan(
train_loader, test_loader, num_epoch=num_epoch,
lr=lr, beta1=beta1, beta2=beta2
)
3.3 Evaluating the generator of our CycleGAN¶
Let’s visualize a few generated T2-weighted images:
plt.figure(figsize=(20, 20))
im = img.imread(f'./images/cyclegan/epoch-{num_epoch - 1}.png')
plt.imshow(np.swapaxes(im, 0, 1))
plt.gca().invert_yaxis()
plt.show()
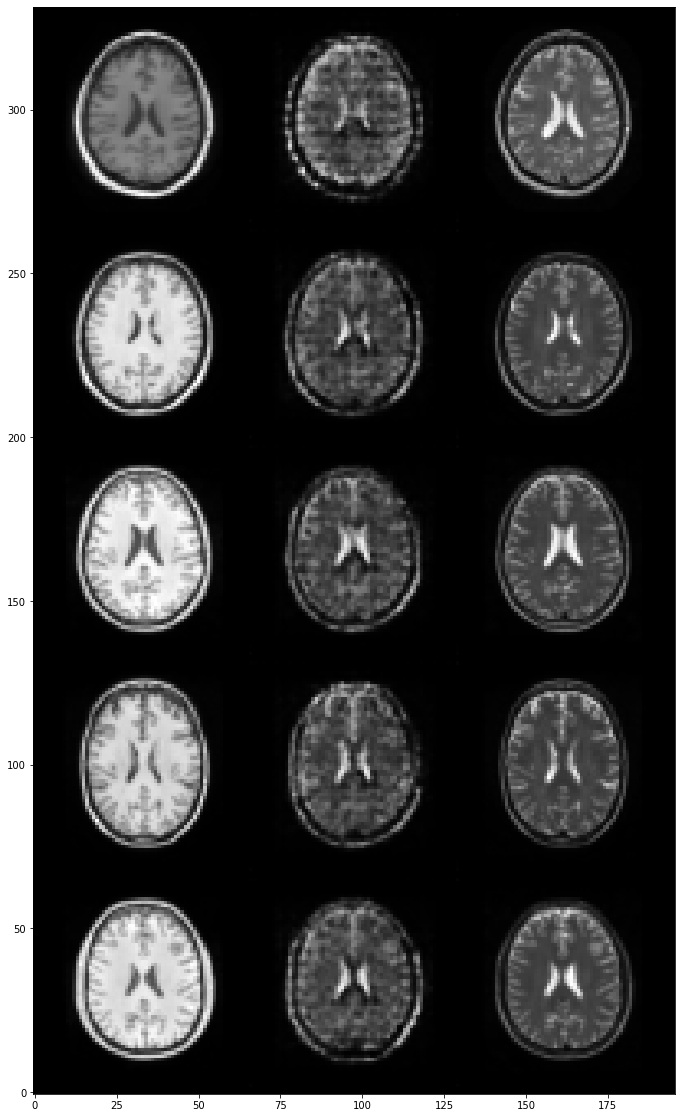
We will now evaluate the generator of the CycleGAN with the same three metrics on both the training set and the test set by computing the mean value for each metric.
evaluate_generator(generator_cyclegan)
| Training set | Test set | |
|---|---|---|
| MAE | 0.085963 | 0.086542 |
| PSNR | 14.906391 | 14.870862 |
| SSIM | 0.889677 | 0.887021 |
You should obtain a lower performance for the CycleGAN, which is not so surprising since this task is unsupervised whereas the two other tasks are supervised.
It does not mean that cycle GAN are not useful in practice. Datasets of unpaired samples are much more common than datasets of paired samples. Here is an example of transforming a picture into a painting from a famous painter using a CycleGAN (taken from the original paper introducing CycleGAN):